Introduction
MMTk is a memory management toolkit providing language implementers with a powerful memory management framework and researchers with a multi-runtime platform for memory management research. It is a complete re-write of the original MMTk, which was written in Java as part of Jikes RVM.
Glossary
This document explains basic concepts of garbage collection. MMTk uses those terms as described in this document. Different VMs may define some terms differently. Should there be any confusion, this document will help disambiguating them. We use the book The Garbage Collection Handbook: The Art of Automatic Memory Management as the primary reference.
Object graph
Object graph is a graph-theory view of the garbage-collected heap. An object graph is a directed graph that contains nodes and edges. An edge always points to a node. But unlike conventional graphs, an edge may originate from either another node or a root.
Each node represents an object in the heap.
Each edge represents an object reference from an object or a root. A root is a reference held in a slot directly accessible from mutators, including local variables, global variables, thread-local variables, and so on. A object can have many fields, and some fields may hold references to objects, while others hold non-reference values.
An object is reachable if there is a path in the object graph from any root to the node of the object. Unreachable objects cannot be accessed by mutators. They are considered garbage, and can be reclaimed by the garbage collector.
Mutator
TODO
Emergency Collection
Also known as: emergency GC
In MMTk, an emergency collection happens when a normal collection cannot reclaim enough memory to satisfy allocation requests. Plans may do full-heap GC, defragmentation, etc. during emergency collections in order to free up more memory.
VM bindings can call MMTK::is_emergency_collection to query if the current GC is an emergency GC.
During emergency GC, the VM binding is recommended to retain fewer objects than normal GCs, to the
extent allowed by the specification of the VM or the language. For example, the VM binding may
choose not to retain objects used for caching. Specifically, for Java virtual machines, that means
not retaining referents of SoftReference which is primarily designed for
implementing memory-sensitive caches.
GC-safe Point
Also known as: GC-point
A GC-safe point is a place in the code executed by mutators where (stop-the-world) garbage collection is allowed to happen. Concurrent GC can run concurrently with mutators, but still needs to synchronize with mutators at GC-safe points. Regardless, the following statements must be true when a mutator is at a GC-safe point.
- References held by a mutator can be identified. That include references in local variables, thread-local variables, and so on. For compiled code, that include those in stack slots and machine registers.
- The mutator cannot be in the middle of operations that must be atomic with respect to GC. That includes write barriers, address-based hashing, etc.
Code With GC Semantics
Compilers (including ahead-of-time and just-in-time compilers) for programs with garbage collection semantics (such as Java source code or bytecode) usually understand GC semantics, too, and can generate yieldpoints and stack maps to assist GC.
In practice, such compilers only make certain places in a function GC-safe and only generate stack maps at those places, including but not limited to:
- yieldpoints
- object allocation sites (may trigger GC)
- call sites to other functions where GC is allowed to happen inside
If we allow GC to happen at arbitrary PC, it will either force the compiler to generate stack maps at all PCs, or force the VM to use shadow stacks or conservative stack scanning, instead. It will also break operations that must be atomic with respect to GC, such as write barrier and address-based hashing.
Code Without GC Semantics
In contrast, for programs without GC semantics (e.g. programs written in C, C++, Rust, etc.), their compilers (GCC, clang, rustc, ...) are agnostic to GC. But many VMs (such as OpenJDK, CRuby, Julia, etc.) are implemented in such languages. We don't usually use the term "GC-safe point" for functions written in C, C++, Rust, etc., but each VM has its own rules to determine whether GC can happen within functions written in those languages.
Interpreters usually maintain local variables in dedicated stacks or frames data structures. References in such structures are identified by traversing those stacks or frames, and GC is usually allowed between bytecode instructions.
Some runtime functions implement operations tightly related to GC, and must be atomic w.r.t. GC. For example, if a function initializes the type information in the header of an object, GC cannot happen in the middle. Otherwise the GC will read a corrupted header and crash. Other examples include functions that implement the write barrier slow path and address-based hashing. Such functions cannot allocate objects, and cannot call any function that may trigger GC.
Some functions do not access the GC heap, or only access the heap in controlled ways (e.g. utilizing
object pinning, or via safe APIs such as JNI). Some of such functions (such as wrappers for
blocking system calls including read and write) are long-running. GC is usually safe when some
mutators are executing such functions. Compilers for languages with GC semantics usually make call
sites to such functions GC-safe points, and generate stack maps at those call sites. The
runtime usually transitions the state of the current mutator thread so that the GC knows it is in
such a function when requesting all mutators to stop at their next GC-safe points.
Stack Map
A stack map is a data structure that identifies stack slots and registers that may contain references. Stack maps are essential for supporting precise stack scanning.
Yieldpoint
Also known as: GC-check point
A yieldpoint is a point in a program where a mutator thread checks if it should yield from normal execution in order to handle certain events, such as garbage collection, profiling, biased lock revocation, etc.
Compilers of programs with GC semantics (e.g. Java source code and byte code) insert yieldpoints in various places, such as function epilogues and loop back-edges. In this way, when GC is triggered asynchronously by other threads, the current mutator can reach the next yieldpoint quickly and yield for GC promptly. Compilers also generate stack maps at yieldpoints to make them GC-safe points.
Because some operations (such as write barrier) must be atomic w.r.t. GC, yieldpoints must not be inserted in the middle of such operations.
Read the paper Stop and go: Understanding yieldpoint behavior by Lin et al. for more details.
Address-based Hashing
Address-based hashing is a GC-assisted space-efficient high-performance method for implementing identity hash code in copying GC.
Read the Address-based Hashing chapter for more details.
Precise Stack Scanning
Also known as: exact stack scanning
TODO
Conservative Stack Scanning
TODO
Shadow Stack
TODO
Write Barrier
TODO
Fast Path and Slow Path
TODO
Object Pinning
TODO
MMTk Tutorial
In this tutorial, you will build multiple garbage collectors from scratch using MMTk. You will start with an incredibly simple 'collector' called NoGC, and through a series of additions and refinements end up with a generational copying garbage collector.
This tutorial is aimed at GC implementors who would like to implement new GC algorithms/plans with MMTk. If you are a language implementor interested in porting your runtime to MMTk, you should refer to the porting guide instead.
This tutorial is a work in progress. Some sections may be rough, and others may be missing information (especially about import statements). If something is missing or inaccurate, refer to the relevant completed garbage collector if possible. Please also raise an issue, or create a pull request addressing the problem.
Introduction
In this section, we introduce MMTk and this tutorial. We will cover what MMTk is, what this tutorial covers, and a glossary of terms that will be used throughout the tutorial. If you are already familiar with MMTk and garbage collection terminology, you may skim through this section and move on to the preliminaries.
What is MMTk?
The Memory Management Toolkit (MMTk) is a framework for designing and implementing memory managers. It has a runtime-neutral core (mmtk-core) written in Rust, and bindings that allow it to work with OpenJDK, V8, and JikesRVM, with more bindings currently in development. MMTk was originally written in Java as part of the JikesRVM Java runtime. The current version is similar in its purpose, but was made to be very flexible with runtime and able to be ported to many different VMs.
The principal idea of MMTk is that it can be used as a toolkit, allowing new GC algorithms to be rapidly developed using common components. It also allows different GC algorithms to be compared on an apples-to-apples basis, since they share common mechanisms.
What will this tutorial cover?
This tutorial is intended to get you comfortable constructing new plans in MMTk.
You will first be guided through building a semispace collector. After that, you will extend this collector to be a generational collector, to further familiarise you with different concepts in MMTk. There will also be questions and exercises at various points in the tutorial, intended to encourage you to think about what the code is doing, increase your general understanding of MMTk, and motivate further research.
Where possible, there will be links to finished, functioning code after each section so that you can check that your code is correct. Note, however, that these will be full collectors. Therefore, there may be some differences between these files and your collector due to your position in the tutorial. By the end of each major section, your code should be functionally identical to the finished code provided.
Furthermore, please note that this code may not be identical to the main code of the MMTk. It is deliberately kept separate as a simpler stable version. Make sure to refer to the provided tutorial code and not the main collector code during the tutorial.
Glossary
allocator: Code that allocates new objects into memory.
collector: Finds and frees memory occupied by 'dead' objects.
dead: An object that is not live.
GC work (unit), GC packet: A schedulable unit of collection work.
GC worker: A worker thread that performs garbage collection operations (as required by GC work units).
live: An object that is reachable, and thus can still be accessed by other objects, is live/alive.
mutator: Something that 'mutates', or changes, the objects stored in memory. This is the term that is traditionally used in the garbage collection literature to describe the running program (because it 'mutates' the object graph).
plan: A garbage collection algorithm expressed as a configuration of policies. See also Plans and policies below.
policy: A specific garbage collection algorithm, such as marksweep, copying, immix, etc. Plans are made up of an arrangement of one or more policies. See also Plans and policies below.
scheduler: Dynamically dispatches units of GC work to workers.
zeroing, zero initialization: Initializing and resetting unused memory bits to have a value of 0. Required by most memory-safe programming languages.
See also: Further Reading
Plans and Policies
In MMTk, collectors are instantiated as plans, which can be thought of as configurations of collector policies. In practice, most production collectors and almost all collectors in MMTk are comprised of multiple algorithms/policies. For example the gencopy plan describes a configuration that combines a copying nursery with a semispace mature space. In MMTk we think of these as three spaces, each of which happen to use the copyspace policy, and which have a relationship which is defined by the gencopy plan. Under the hood, gencopy builds upon a common plan which may also contain other policies including a space for code, a read-only space, etc.
Thus, someone wishing to construct a new collector based entirely on existing policies may be able to do so in MMTk by simply writing a new plan, which is what this tutorial covers.
On the other hand, someone wishing to introduce an entirely new garbage collection policy (such as Immix, for example), would need to first create a policy which specifies that algorithm, before creating a plan which defines how the GC algorithm fits together and utilizes that policy.
Preliminaries
In this section, we set up the environment for the tutorial. We will set up MMTk and OpenJDK (the binding used throughout the tutorial), and test the build to make sure everything works before moving on to building a new collector.
Set up MMTk and OpenJDK
This tutorial can be completed with any binding. However, for the sake of simplicity, only the setup for the OpenJDK binding will be described in detail here. If you would like to use another binding, you will need to follow the README files in their respective repositories (JikesRVM, V8) to set them up, and find appropriate benchmarks for testing. Also, while it may be useful to fork the relevant repositories to your own account, it is not required for this tutorial.
First, set up OpenJDK, MMTk, and the binding:
- Clone the OpenJDK binding and mmtk-core repository, and install any relevant dependencies by following the instructions in the OpenJDK binding repository.
- Ensure you can build OpenJDK according to the instructions in the READMEs of
the mmtk-core repository and the
OpenJDK binding repository.
- Use the
slowdebugoption when building the OpenJDK binding. This is the fastest debug variant to build, and allows for easier debugging and better testing. The rest of the tutorial will assume you are usingslowdebug. - You can use the env var
MMTK_PLAN=[PlanName]to choose a plan to use at run-time. The plans that are relevant to this tutorial areNoGCandSemiSpace. - Make sure you only use the env var
MMTK_PLAN=[PlanName]when you run the generatedjavabinary (./build/linux-x86_64-normal-server-$DEBUG_LEVEL/jdk/bin/java). Do not setMMTK_PLANwhen you build OpenJDK (if you already have set the env varMMTK_PLAN, you would need to doexport MMTK_PLAN=orunset MMTK_PLANto clear the env var before building).
- Use the
The MMTk OpenJDK binding ships with a fixed version of mmtk-core, specified in mmtk-openjdk/mmtk/Cargo.toml.
For local development, you would need to build the binding with a local copy of the mmtk-core repo that you
can modify. You would need to point the mmtk dependency to a local path.
- Find
mmtkunder[dependencies]inmmtk-openjdk/mmtk/Cargo.toml. It should point to the mmtk-core git path with a specific revision. - Comment out the line for the git dependency, and uncomment the following line for a local dependency.
- The local dependency points to
mmtk-openjdk/repos/mmtk-coreby default. If your local mmtk-core path is notmmtk-openjdk/repos/mmtk-core, modify the path to point to your local mmtk-core. - Rebuild the OpenJDK binding.
Test the build
A few benchmarks of varying size will be used throughout the tutorial. If you
haven't already, set them up now. All of the following commands should be
entered in repos/openjdk.
-
HelloWorld (simplest, will never trigger GC):
- Copy the following code into a new Java file titled "HelloWorld.java"
in
mmtk-openjdk/repos/openjdk:class HelloWorld { public static void main(String[] args) { System.out.println("Hello World!"); } } - Use the command
./build/linux-x86_64-normal-server-$DEBUG_LEVEL/jdk/bin/javac HelloWorld.java. - Then, run
./build/linux-x86_64-normal-server-$DEBUG_LEVEL/jdk/bin/java -XX:+UseThirdPartyHeap HelloWorldto run HelloWorld. - If your program printed out
Hello World!as expected, then congratulations, you have MMTk working with OpenJDK!
- Copy the following code into a new Java file titled "HelloWorld.java"
in
-
The Computer Language Benchmarks Game fannkuchredux (micro benchmark, allocates a small amount of memory but - depending on heap size and the GC plan - may not trigger a collection):
- Copy this code
into a new file named "fannkuchredux.java"
in
mmtk-openjdk/repos/openjdk. - Use the command
./build/linux-x86_64-normal-server-$DEBUG_LEVEL/jdk/bin/javac fannkuchredux.java. - Then, run
./build/linux-x86_64-normal-server-$DEBUG_LEVEL/jdk/bin/java -XX:+UseThirdPartyHeap fannkuchreduxto run fannkuchredux.
- Copy this code
into a new file named "fannkuchredux.java"
in
-
DaCapo benchmark suite (most complex, will likely trigger multiple collections):
- Fetch using
wget https://sourceforge.net/projects/dacapobench/files/9.12-bach-MR1/dacapo-9.12-MR1-bach.jar/download -O ./dacapo-9.12-MR1-bach.jar. - DaCapo contains a variety of benchmarks, but this tutorial will only be
using lusearch. Run the lusearch benchmark using the command
./build/linux-x86_64-normal-server-$DEBUG_LEVEL/jdk/bin/java -XX:+UseThirdPartyHeap -Xms512M -Xmx512M -jar ./dacapo-9.12-MR1-bach.jar lusearchinrepos/openjdk.
- Fetch using
Rust Logs
By using one of the debug builds, you gain access to the Rust logs - a useful
tool when testing a plan and observing the general behaviour of MMTk.
There are two levels of trace that are useful when using MMTk - trace
and debug. Generally, debug logs information about the slow paths
(allocation through MMTk, rather than fast path allocation through the binding).
trace includes all the information from debug, plus more information about
both slow and fast paths and garbage collection activities. You can set which
level to view the logs at by setting the environment variable RUST_LOG. For
more information, see the
env_logger crate documentation.
Working with different GC plans
You will be using multiple GC plans in this tutorial. You should familiarise yourself with how to do this now.
- The OpenJDK build will always generate in
mmtk-openjdk/repos/openjdk/build. From the same build, you can run different GC plans by using the environment variableMMTK_PLAN=[PlanName]. Generally you won't need multiple VM builds. However, if you do need to keep a build (for instance, to make quick performance comparisons), you can do the following: rename either thebuildfolder or the folder generated within it (eglinux-x86_64-normal-server-$DEBUG_LEVEL).- Renaming the
buildfolder is the safest method for this. - If you rename the internal folder, there is a possibility that the new build will generate incorrectly. If a build appears to generate strangely quickly, it probably generated badly.
- A renamed build folder can be tested by changing the file path in commands as appropriate.
- If you plan to completely overwrite a build, deleting the folder you are writing over will help prevent errors.
- Renaming the
- Try running your build with
NoGC. Both HelloWorld and the fannkuchredux benchmark should run without issue. If you then run lusearch, it should fail when a collection is triggered. It is possible to increase the heap size enough that no collections will be triggered, but it is okay to let it fail for now. When we build using a proper GC, it will be able to pass. The messages and errors produced should look identical or nearly identical to the log below.$ MMTK_PLAN=NoGC ./build/linux-x86_64-normal-server-$DEBUG_LEVEL/jdk/bin/java -XX:+UseThirdPartyHeap -Xms512M -Xmx512M -jar ./dacapo-9.12-MR1-bach.jar lusearch Using scaled threading model. 24 processors detected, 24 threads used to drive the workload, in a possible range of [1,64] Warning: User attempted a collection request, but it is not supported in NoGC. The request is ignored. ===== DaCapo 9.12-MR1 lusearch starting ===== [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection thread '<unnamed>' panicked at 'internal error: entered unreachable code: GC triggered in nogc', /opt/rust/toolchains/nightly-2020-07-08-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/src/libstd/macros.rs:16:9 note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection [2020-12-18T00:27:49Z INFO mmtk::plan::global] [POLL] nogc_space: Triggering collection fatal runtime error: failed to initiate panic, error 5 Aborted (core dumped) - Try running your build with
SemiSpace. lusearch should now pass, as garbage will be collected, and the smaller benchmarks should run the same as they did while using NoGC.MMTK_PLAN=SemiSpace ./build/linux-x86_64-normal-server-$DEBUG_LEVEL/jdk/bin/java -XX:+UseThirdPartyHeap -Xms512M -Xmx512M -jar ./dacapo-9.12-MR1-bach.jar lusearch
MyGC
In this section, we will build a new garbage collector from scratch, called
MyGC. We will start by creating MyGC as a copy of the simple NoGC plan,
which only allocates memory and never collects. We will then extend it step
by step into a semispace collector, and finally into a generational copying
collector.
Create MyGC
NoGC is a GC plan that only allocates memory, and does not have a collector. We're going to use it as a base for building a new garbage collector.
Recall that this tutorial will take you through the steps of building a
collector from basic principles. To do that, you'll create your own plan
called MyGC which you'll gradually refine and improve upon through the
course of this tutorial. At the beginning MyGC will resemble the very
simple NoGC plan.
- Each plan is stored in
mmtk-openjdk/repos/mmtk-core/src/plan. Navigate there and create a copy of the foldernogc. Rename it tomygc. - In each file within
mygc, rename any reference tonogctomygc. You will also have to separately rename any reference toNoGCtoMyGC.- For example, in Visual Studio Code, you can (making sure case sensitivity
is selected in the search function) select one instance of
nogcand either right click and select "Change all instances" or use the CTRL-F2 shortcut, and then typemygc, and repeat forNoGC.
- For example, in Visual Studio Code, you can (making sure case sensitivity
is selected in the search function) select one instance of
- In order to use MyGC, you will need to make some changes to the following
files.
mmtk-core/src/plan/mod.rs, add:
This adds#![allow(unused)] fn main() { pub mod mygc; }mygcas a module.mmtk-core/src/util/options.rs, addMyGCto the enumPlanSelector. This allows MMTk to acceptMyGCas a command line option forplan, or an environment variable forMMTK_PLAN:#![allow(unused)] fn main() { #[derive(Copy, Clone, EnumFromStr, Debug)] pub enum PlanSelector { NoGC, SemiSpace, GenCopy, GenImmix, MarkSweep, PageProtect, Immix, // Add this! MyGC, } }mmtk-core/src/plan/global.rs, add new expressions tocreate_mutator()andcreate_plan()forMyGC, following the pattern of the existing plans. These define the location of the mutator and plan's constructors.#![allow(unused)] fn main() { // NOTE: Sections of this code snippet not relevant to this step of the // tutorial (marked by "// ...") have been omitted. pub fn create_mutator<VM: VMBinding>( tls: VMMutatorThread, mmtk: &'static MMTK<VM>, ) -> Box<Mutator<VM>> { Box::new(match mmtk.options.plan { PlanSelector::NoGC => crate::plan::nogc::mutator::create_nogc_mutator(tls, &*mmtk.plan), PlanSelector::SemiSpace => { crate::plan::semispace::mutator::create_ss_mutator(tls, &*mmtk.plan) } // ... // Create MyGC mutator based on selector PlanSelector::MyGC => crate::plan::mygc::mutator::create_mygc_mutator(tls, &*mmtk.plan), }) } pub fn create_plan<VM: VMBinding>( plan: PlanSelector, vm_map: &'static VMMap, mmapper: &'static Mmapper, options: Arc<UnsafeOptionsWrapper>, ) -> Box<dyn Plan<VM = VM>> { match plan { PlanSelector::NoGC => Box::new(crate::plan::nogc::NoGC::new(args)), PlanSelector::SemiSpace => Box::new(crate::plan::semispace::SemiSpace::new(args)), // ... // Create MyGC plan based on selector PlanSelector::MyGC => Box::new(crate::plan::mygc::MyGC::new(args)) } } }
Note that all of the above changes almost exactly copy the NoGC entries in each of these files. However, NoGC has some variants, such as a lock-free variant. For simplicity, those are not needed for this tutorial. Remove references to them in the MyGC plan now.
- Within
mygc/global.rs, find any use of#[cfg(feature = "mygc_lock_free")]and delete both it and the line below it. - Then, delete any use of the above line's negation,
#[cfg(not(feature = "mygc_lock_free"))], this time without changing the line below it.
After you rebuild OpenJDK (and mmtk-core), you can run MyGC with your new
build (MMTK_PLAN=MyGC). Try testing it with the each of the three benchmarks.
It should work identically to NoGC.
If you've got to this point, then congratulations! You have created your first working MMTk collector!
At this point, you should familiarise yourself with the MyGC plan if you haven't already. Try answering the following questions by looking at the code and Further Reading:
- Where is the allocator defined?
- How many memory spaces are there?
- What kind of memory space policy is used?
- What happens if garbage has to be collected?
Building a semispace collector
In a semispace collector, the heap is divided into two equally-sized spaces, called 'semispaces'. One of these is defined as a 'fromspace', and the other a 'tospace'. The allocator allocates to the tospace until it is full.
When the tospace is full, a stop-the-world GC is triggered. The mutator is paused, and the definitions of the spaces are flipped (the 'tospace' becomes a 'fromspace', and vice versa). Then, the collector scans each object in what is now the fromspace. If a live object is found, a copy of it is made in the tospace. That is to say, live objects are copied from the fromspace to the tospace. After every object is scanned, the fromspace is cleared. The GC finishes, and the mutator is resumed.
Allocation: Add copyspaces
We will now change your MyGC plan from one that cannot collect garbage into one that implements the semispace algorithm. The first step of this is to add the two copyspaces, and allow collectors to allocate memory into them. This involves adding two copyspaces, the code to properly initialise and prepare the new spaces, and a copy context.
Change the plan constraints
Firstly, change the plan constraints. Some of these constraints are not used at the moment, but it's good to set them properly regardless.
Look in plan/plan_constraints.rs. PlanConstraints lists all the possible
options for plan-specific constraints. At the moment, MYGC_CONSTRAINTS in
mygc/global.rs should be using the default value for PlanConstraints.
We will make the following changes:
- Initialize
gc_header_bitsto 2. We reserve 2 bits in the header for GC use. - Initialize
moves_objectstotrue.
Finished code (step 1-3):
pub const MYGC_CONSTRAINTS: PlanConstraints = PlanConstraints {
moves_objects: true,
..PlanConstraints::default()
};
Change the plan implementation
Next, in mygc/global.rs, replace the old immortal (nogc) space with two
copyspaces.
Imports
To the import statement block:
- Replace
crate::plan::global::{BasePlan, NoCopy};withuse crate::plan::global::BasePlan;. This collector is going to use copying, so there's no point to importing NoCopy any more. - Add
use crate::plan::global::CommonPlan;. Semispace uses the common plan, which includes an immortal space and a large object space, rather than the base plan. Any garbage collected plan should useCommonPlan. - Add
use std::sync::atomic::{AtomicBool, Ordering};. These are going to be used to store an indicator of which copyspace is the tospace. - Delete
#[allow(unused_imports)].
Finished code (step 1):
#![allow(unused)] fn main() { use crate::plan::global::BasePlan; //Modify use crate::plan::global::CommonPlan; // Add use crate::plan::global::{CreateGeneralPlanArgs, CreateSpecificPlanArgs}; use crate::plan::mygc::mutator::ALLOCATOR_MAPPING; use crate::plan::mygc::gc_work::MyGCWorkContext; use crate::plan::AllocationSemantics; use crate::plan::Plan; use crate::plan::PlanConstraints; use crate::policy::copyspace::CopySpace; // Add use crate::policy::space::Space; use crate::scheduler::*; // Modify use crate::util::alloc::allocators::AllocatorSelector; use crate::util::copy::*; use crate::util::heap::VMRequest; use crate::util::heap::gc_trigger::SpaceStats; use crate::util::metadata::side_metadata::SideMetadataContext; use crate::util::opaque_pointer::*; use crate::vm::VMBinding; use enum_map::EnumMap; use std::sync::atomic::{AtomicBool, Ordering}; // Add }
Struct MyGC
Change pub struct MyGC<VM: VMBinding> to add new instance variables.
- Delete the existing fields in the constructor.
- Add
pub hi: AtomicBool,. This is a thread-safe bool, indicating which copyspace is the tospace. - Add
pub copyspace0: CopySpace<VM>,andpub copyspace1: CopySpace<VM>,. These are the two copyspaces. - Add
pub common: CommonPlan<VM>,. This holds an instance of the common plan.
Finished code (step 2):
#![allow(unused)] fn main() { #[derive(HasSpaces, PlanTraceObject)] pub struct MyGC<VM: VMBinding> { pub hi: AtomicBool, #[space] #[copy_semantics(CopySemantics::DefaultCopy)] pub copyspace0: CopySpace<VM>, #[space] #[copy_semantics(CopySemantics::DefaultCopy)] pub copyspace1: CopySpace<VM>, #[parent] pub common: CommonPlan<VM>, } }
Note that MyGC now also derives PlanTraceObject besides HasSpaces, and we
have attributes on some fields. These attributes tell MMTk's macros how to
generate code to visit each space of this plan as well as trace objects in this
plan. Although there are other approaches that you can implement object
tracing, in this tutorial we use the macros, as it is the simplest. Make sure
you import the macros. We will discuss on what those attributes mean in later
sections.
#![allow(unused)] fn main() { use mmtk_macros::{HasSpaces, PlanTraceObject}; }
Implement the Plan trait for MyGC
Constructor
Change fn new(). This section initialises and prepares the objects in MyGC
that you just defined.
- Delete the definition of
mygc_space. Instead, we will define the two copyspaces here. - Define one of the copyspaces by adding the following code:
#![allow(unused)] fn main() { copyspace0: CopySpace::new(plan_args.get_normal_space_args("copyspace0", true, false, VMRequest::discontiguous()), false), }
- Create another copyspace, called
copyspace1, defining it as a fromspace instead of a tospace. (Hint: the definitions for copyspaces are insrc/policy/copyspace.rs.) - Finally, replace the old MyGC initializer.
#![allow(unused)] fn main() { fn new(args: CreateGeneralPlanArgs<VM>) -> Self { // Modify let mut plan_args = CreateSpecificPlanArgs { global_args: args, constraints: &MYGC_CONSTRAINTS, global_side_metadata_specs: SideMetadataContext::new_global_specs(&[]), }; MyGC { hi: AtomicBool::new(false), copyspace0: CopySpace::new(plan_args.get_normal_space_args("copyspace0", true, false, VMRequest::discontiguous()), false), copyspace1: CopySpace::new(plan_args.get_normal_space_args("copyspace1", true, false, VMRequest::discontiguous()), true), common: CommonPlan::new(plan_args), } } }
Access MyGC spaces
Add a new section of methods for MyGC:
#![allow(unused)] fn main() { impl<VM: VMBinding> MyGC<VM> { } }
To this, add two helper methods, tospace(&self)
and fromspace(&self). They both have return type &CopySpace<VM>,
and return a reference to the tospace and fromspace respectively.
tospace() (see below) returns a reference to the tospace,
and fromspace() returns a reference to the fromspace.
We also add another two helper methods to get tospace_mut(&mut self)
and fromspace_mut(&mut self). Those will be used later when we implement
collection for our GC plan.
#![allow(unused)] fn main() { pub fn tospace(&self) -> &CopySpace<VM> { if self.hi.load(Ordering::SeqCst) { &self.copyspace1 } else { &self.copyspace0 } } pub fn fromspace(&self) -> &CopySpace<VM> { if self.hi.load(Ordering::SeqCst) { &self.copyspace0 } else { &self.copyspace1 } } pub fn tospace_mut(&mut self) -> &mut CopySpace<VM> { if self.hi.load(Ordering::SeqCst) { &mut self.copyspace1 } else { &mut self.copyspace0 } } pub fn fromspace_mut(&mut self) -> &mut CopySpace<VM> { if self.hi.load(Ordering::SeqCst) { &mut self.copyspace0 } else { &mut self.copyspace1 } } }
Other methods in the Plan trait
The trait Plan requires a common() method that should return a
reference to the common plan. Implement this method now.
#![allow(unused)] fn main() { fn common(&self) -> &CommonPlan<VM> { &self.common } }
Find the helper method base and change it so that it calls the
base plan through the common plan.
#![allow(unused)] fn main() { fn base(&self) -> &BasePlan<VM> { &self.common.base } fn base_mut(&mut self) -> &mut BasePlan<Self::VM> { &mut self.common.base } }
The trait Plan requires collection_required() method to know when
we should trigger a collection. We can just use the implementation
in the BasePlan.
#![allow(unused)] fn main() { fn collection_required(&self, space_full: bool, _space: Option<SpaceStats<Self::VM>>) -> bool { self.base().collection_required(self, space_full) } }
Find the method get_pages_used. Replace the current body with
self.tospace().reserved_pages() + self.common.get_pages_used(), to
correctly count the pages contained in the tospace and the common plan
spaces (which will be explained later).
#![allow(unused)] fn main() { fn get_used_pages(&self) -> usize { self.tospace().reserved_pages() + self.common.get_used_pages() } }
Add and override the following helper function:
#![allow(unused)] fn main() { fn get_collection_reserved_pages(&self) -> usize { self.tospace().reserved_pages() } }
Change the mutator definition
Next, we need to change the mutator, in mutator.rs, to allocate to the
tospace, and to the two spaces controlled by the common plan.
Imports
Change the following import statements:
- Add
use super::MyGC;. - Add
use crate::util::alloc::BumpAllocator;. - Delete
use crate::plan::mygc::MyGC;.
#![allow(unused)] fn main() { use super::MyGC; // Add use crate::MMTK; use crate::plan::barriers::NoBarrier; use crate::plan::mutator_context::Mutator; use crate::plan::mutator_context::MutatorConfig; use crate::plan::AllocationSemantics; use crate::util::alloc::allocators::{AllocatorSelector, Allocators}; use crate::util::alloc::BumpAllocator; use crate::util::opaque_pointer::*; use crate::vm::VMBinding; use crate::plan::mutator_context::{ create_allocator_mapping, create_space_mapping, ReservedAllocators, }; use enum_map::EnumMap; // Remove crate::plan::mygc::MyGC // Remove mygc_mutator_noop }
Allocator mapping
In lazy_static!, make the following changes to ALLOCATOR_MAPPING,
which maps the required allocation semantics to the corresponding allocators.
For example, for Default, we allocate using the first bump pointer allocator
(BumpPointer(0)):
- Define a
ReservedAllocatorsinstance to declare that we need one bump allocator. - Map the common plan allocators using
create_allocator_mapping. - Map
DefaulttoBumpPointer(0).
#![allow(unused)] fn main() { const RESERVED_ALLOCATORS: ReservedAllocators = ReservedAllocators { n_bump_pointer: 1, ..ReservedAllocators::DEFAULT }; lazy_static! { pub static ref ALLOCATOR_MAPPING: EnumMap<AllocationSemantics, AllocatorSelector> = { let mut map = create_allocator_mapping(RESERVED_ALLOCATORS, true); map[AllocationSemantics::Default] = AllocatorSelector::BumpPointer(0); map }; } }
Space mapping
Next, in create_mygc_mutator, change which allocator is allocated to what
space in space_mapping. Note that the space allocation is formatted as a list
of tuples. For example, the first bump pointer allocator (BumpPointer(0)) is
bound with tospace.
Downcast the dynamic Plan type to MyGC so we can access specific spaces in
MyGC.
#![allow(unused)] fn main() { let mygc = mmtk.get_plan().downcast_ref::<MyGC<VM>>().unwrap(); }
Then, use mygc to access the spaces in MyGC.
BumpPointer(0)should map to the tospace.- Other common plan allocators should be mapped using
create_space_mapping. - None of the above should be dereferenced (ie, they should not have
the
&prefix).
#![allow(unused)] fn main() { space_mapping: Box::new({ let mut vec = create_space_mapping(RESERVED_ALLOCATORS, true, mygc); vec.push((AllocatorSelector::BumpPointer(0), mygc.tospace())); vec }), }
The create_space_mapping and create_allocator_mapping call that have appeared all
of a sudden in these past 2 steps, are parts of the MMTk common plan
itself. They are used to construct allocator-space mappings for the spaces defined
by the common plan:
- The immortal space is used for objects that the virtual machine or a library never expects to die.
- The large object space is needed because MMTk handles particularly large objects differently to normal objects, as the space overhead of copying large objects is very high. Instead, this space is used by a free list allocator in the common plan to avoid having to copy them.
- The read-only space is used to store all the immutable objects.
- The code spaces are used for VM generated code objects.
With this, you should have the allocation working, but not garbage collection. Try building again. If you run HelloWorld or Fannkunchredux, they should work. DaCapo's lusearch should fail, as it requires garbage to be collected.
Collection: Implement garbage collection
We need to add a few more things to get garbage collection working.
Specifically, we need to config the GCWorkerCopyContext, which a GC worker uses for
copying objects, and GC work packets that will be scheduled for a collection.
CopyConfig
CopyConfig defines how a GC plan copies objects.
Similar to the MutatorConfig struct, you would need to define CopyConfig for your plan.
In impl<VM: VMBinding> Plan for MyGC<VM>, override the method create_copy_config().
The default implementation provides a default CopyConfig for non-copying plans. So for non-copying plans,
you do not need to override the method. But
for copying plans, you would have to provide a proper copy configuration.
In a semispace GC, objects will be copied between the two copy spaces. We will use one
CopySpaceCopyContext for the copying, and will rebind the copy context to the proper tospace
in the preparation step of a GC (which will be discussed later when we talk about preparing for collections).
We use CopySemantics::DefaultCopy for our copy
operation, and bind it with the first CopySpaceCopyContext (CopySemantics::DefaultCopy => CopySelector::CopySpace(0)).
Other copy semantics are unused in this plan. We also provide an initial space
binding for CopySpaceCopyContext. However, we will flip tospace in every GC, and rebind the
copy context to the new tospace in each GC, so it does not matter which space we use as the initial
space here.
#![allow(unused)] fn main() { fn create_copy_config(&'static self) -> CopyConfig<Self::VM> { use enum_map::enum_map; CopyConfig { copy_mapping: enum_map! { CopySemantics::DefaultCopy => CopySelector::CopySpace(0), _ => CopySelector::Unused, }, space_mapping: vec![ // The tospace argument doesn't matter, we will rebind before a GC anyway. (CopySelector::CopySpace(0), &self.copyspace0) ], constraints: &MYGC_CONSTRAINTS, } } }
Because the semispace GC copies objects in every single GC, we modify the method
current_gc_may_move_object() in MyGC so that it always returns true.
#![allow(unused)] fn main() { fn current_gc_may_move_object(&self) -> bool { true } }
Introduce collection to MyGC plan
Add a new method to Plan for MyGC, schedule_collection(). This function
runs when a collection is triggered. It schedules GC work for the plan, i.e.,
it stops all mutators, runs the
scheduler's prepare stage and resumes the mutators. The StopMutators work
will invoke code from the bindings to scan threads and other roots, and those
scanning work will further push work for a transitive closure.
Though you can add those work packets by yourself, GCWorkScheduler provides a
method schedule_common_work() that will add common work packets for you.
To use schedule_common_work(), first we need to create a type MyGCWorkContext and implement the trait GCWorkContext for it.
We create gc_work.rs and add the following implementation.
Note that we don't override the GCWorkContext::make_roots_work_factory method.
By default, it will use the DefaultRootsWorkFactory which is sufficient for stop-the-world tracing GC.
Also note that we will use the default SFTTrace which provides a general way to trace object.
For plans like semispace, SFTTrace is sufficient.
For more complex GC plans, one can create their own implementaitons of the Trace trait.
We will discuss about this later, and discuss the alternatives.
#![allow(unused)] fn main() { pub struct MyGCWorkContext<VM: VMBinding>(std::marker::PhantomData<VM>); impl<VM: VMBinding> crate::scheduler::GCWorkContext for MyGCWorkContext<VM> { type VM = VM; type PlanType = MyGC<VM>; type DefaultTrace = SFTTrace<Self::VM>; type PinningTrace = UnsupportedTrace<Self::VM>; } }
Then we implement schedule_collection() using MyGCWorkContext and schedule_common_work().
#![allow(unused)] fn main() { fn schedule_collection(&'static self, scheduler: &GCWorkScheduler<VM>) { scheduler.schedule_common_work::<MyGCWorkContext<VM>>(self); } }
Delete handle_user_collection_request(). This function was an override of
a Common plan function to ignore user requested collection for NoGC. Now we
remove it and allow user requested collection.
Prepare for collection
The collector has a number of steps it needs to perform before each collection. We'll add these now.
Prepare plan
In mygc/global.rs, find the method prepare. Delete the unreachable!()
call, and add the following code:
#![allow(unused)] fn main() { fn prepare(&mut self, tls: VMWorkerThread) { self.common.prepare(tls, true); self.hi .store(!self.hi.load(Ordering::SeqCst), Ordering::SeqCst); // Flips 'hi' to flip space definitions let hi = self.hi.load(Ordering::SeqCst); self.copyspace0.prepare(hi); self.copyspace1.prepare(!hi); self.fromspace_mut() .set_copy_for_sft_trace(Some(CopySemantics::DefaultCopy)); self.tospace_mut().set_copy_for_sft_trace(None); } }
This function is called at the start of a collection. It prepares the two spaces in the common plan, flips the definitions for which space is 'to' and which is 'from', then prepares the copyspaces with the new definition.
Note that we call set_copy_for_sft_trace() for both spaces. This step is required
when using SFTTrace to tell the spaces which copy semantic to use for copying.
For fromspace, we use the DefaultCopy semantic, which we have defined earlier in our CopyConfig.
So for objects in fromspace that need to be copied, the policy will use the copy context that binds with
DefaultCopy (which allocates to the tospace) in the GC worker. For tospace, we set its
copy semantics to None, as we do not expect to copy objects from tospace, and if that ever happens,
we will simply panic.
Prepare worker
As we flip tospace for the plan, we also need to rebind the copy context
to the new tospace. We will override prepare_worker() in our Plan implementation.
Plan.prepare_worker() is executed by each GC worker in the preparation phase of a GC. The code
is straightforward -- we get the first CopySpaceCopyContext, and call rebind() on it with
the new tospace.
#![allow(unused)] fn main() { fn prepare_worker(&self, worker: &mut GCWorker<VM>) { unsafe { worker.get_copy_context_mut().copy[0].assume_init_mut() }.rebind(self.tospace()); } }
Prepare mutator
Going back to mutator.rs, create a new function called
mygc_mutator_prepare<VM: VMBinding>(_mutator: &mut Mutator<VM>, _tls: VMWorkerThread).
This function will be called at the preparation stage of a collection (at the start of a
collection) for each mutator. Its body can stay empty, as there aren't any preparation steps for
the mutator in this GC. In create_mygc_mutator(), find the field prepare_func and change it
from &unreachable_prepare_func to &mygc_mutator_prepare.
💡 Hint: If your plan does nothing when preparing mutators, there is an optimization you can do. You may set the plan constraints field
PlanConstraints::needs_prepare_mutatortofalseso that thePrepareMutatorwork packets which callprepare_funcwill not be created in the first place. This optimization is helpful for VMs that run with a large number of mutator threads. If you do this optimization, you may also leave theMutatorConfig::prepare_funcfield as&unreachable_prepare_functo indicate it should not be called.
Release
Finally, we need to fill out the functions that are, roughly speaking, run after each collection.
Release in plan
Find the method release() in mygc/global.rs. Replace the
unreachable!() call with the following code.
#![allow(unused)] fn main() { fn release(&mut self, tls: VMWorkerThread) { self.common.release(tls, true); self.fromspace().release(); } }
This function is called at the end of a collection. It calls the release routines for the common plan spaces and the fromspace.
Release in mutator
Go back to mutator.rs. Create a new function called mygc_mutator_release() that takes the same
inputs as the mygc_mutator_prepare() function above.
#![allow(unused)] fn main() { pub fn mygc_mutator_release<VM: VMBinding>( mutator: &mut Mutator<VM>, _tls: VMWorkerThread, ) { // rebind the allocation bump pointer to the appropriate semispace let bump_allocator = unsafe { mutator .allocators .get_allocator_mut(mutator.config.allocator_mapping[AllocationSemantics::Default]) } .downcast_mut::<BumpAllocator<VM>>() .unwrap(); bump_allocator.rebind( mutator .plan .downcast_ref::<MyGC<VM>>() .unwrap() .tospace(), ); } }
Then go to create_mygc_mutator(), replace &unreachable_release_func in the release_func field
with &mygc_mutator_release. This function will be called at the release stage of a collection
(at the end of a collection) for each mutator. It rebinds the allocator for the Default
allocation semantics to the new tospace. When the mutator threads resume, any new allocations for
Default will then go to the new tospace.
End of GC
Find the method end_of_gc() in mygc/global.rs. Call end_of_gc from the common plan instead.
#![allow(unused)] fn main() { fn end_of_gc(&mut self, tls: VMWorkerThread) { self.common.end_of_gc(tls); } }
Implementing the Trace trait for MyGC
The Trace trait is key for tracing objects in a GC.
A Trace implementation defines how to trace objects.
GCWorkContext specifies a type that implements Trace, and we used SFTTrace earlier.
In this section, we discuss what Trace does, and what the alternatives are.
Approach 1: Use SFTTrace
SFTTrace dispatches the tracing of objects to their respective spaces through Space Function Table (SFT).
As long as all the policies in a plan provide an implementation of sft_trace_object() in their SFT implementations, the plan can use SFTTrace.
Currently most policies provide an implementation for sft_trace_object(), except mark compact and immix.
Those two policies use multiple GC traces, and due to the limitation of SFT, SFT does not allow
multiple sft_trace_object() for a policy.
SFTTrace is the simplest approach when all the policies support it.
Fortunately, we can use it for our GC, semispace.
Approach 2: Derive PlanTraceObject and use PlanTrace
PlanTrace is another general Trace implementation that can be used by most plans.
When a plan implements the PlanTraceObject, it can use PlanTrace.
You can manually provide an implementation of PlanTraceObject for MyGC. But you can also use the derive macro MMTK provides,
and the macro will generate an implementation of PlanTraceObject:
- Make sure
MyGCalready has the#[derive(HasSpaces)]attribute because all plans need to implement theHasSpacestrait anyway. (import the macro properly:use mmtk_macros::HasSpaces) - Add
#[derive(PlanTraceObject)]forMyGC(import the macro properly:use mmtk_macros::PlanTraceObject) - Add both
#[space]and#[copy_semantics(CopySemantics::Default)]to both copy space fields,copyspace0andcopyspace1.#[space]tells the macro that bothcopyspace0andcopyspace1are spaces in theMyGCplan, and the generated trace code will check both spaces.#[copy_semantics(CopySemantics::DefaultCopy)]specifies the copy semantics to use when tracing objects in the corresponding space. - Add
#[parent]tocommon. This tells the macro that there are more spaces defined incommonand its nested structs. If an object is not found in any space with#[space]in this plan, the trace code will try to find the space for the object in the 'parent' plan. In our case, the trace code will proceed by checking spaces in theCommonPlan, as the object may be in large object space or immortal space in the common plan.CommonPlanalso implementsPlanTraceObject, so it knows how to find a space for the object and trace it in the same way.
With the derive macro, your MyGC struct should look like this:
#![allow(unused)] fn main() { #[derive(HasSpaces, PlanTraceObject)] pub struct MyGC<VM: VMBinding> { pub hi: AtomicBool, #[space] #[copy_semantics(CopySemantics::DefaultCopy)] pub copyspace0: CopySpace<VM>, #[space] #[copy_semantics(CopySemantics::DefaultCopy)] pub copyspace1: CopySpace<VM>, #[parent] pub common: CommonPlan<VM>, } }
Once this is done, you can specify PlanTrace as the DefaultTrace in your GC work context:
#![allow(unused)] fn main() { use crate::plan::tracing::PlanTrace; use crate::policy::gc_work::DEFAULT_TRACE; pub struct MyGCWorkContext2<VM: VMBinding>(std::marker::PhantomData<VM>); impl<VM: VMBinding> crate::scheduler::GCWorkContext for MyGCWorkContext2<VM> { type VM = VM; type PlanType = MyGC<VM>; type DefaultTrace = PlanTrace<MyGC<VM>, DEFAULT_TRACE>; type PinningTrace = UnsupportedTrace<Self::VM>; } }
Approach 3: Implement your own Trace
Apart from the two approaches above, you can always implement your own Trace.
This is an overkill for simple plans like semi space, but might be necessary for more complex plans.
We discuss how to implement it for MyGC.
Create a struct MyGCTrace<VM: VMBinding> in the gc_work module.
It includes only a reference back to the plan.
#![allow(unused)] fn main() { pub struct MyGCTrace<VM: VMBinding> { plan: &'static MyGC<VM>, } }
The Trace trait requires the Clone trait,
but you usually can't use #[derive(Clone)] because <VM: VMBinding> does not implement Clone.
You have to implement Clone manually, but it is trivial to do.
#![allow(unused)] fn main() { impl<VM: VMBinding> Clone for MyGCTrace<VM> { fn clone(&self) -> Self { Self { plan: self.plan } } } }
Then implement Trace for MyGCTrace.
It has a VM type member and several methods.
See the comments in the example code below for more details.
For trace_object(), what we do is similar to the approach above (except that we need to write the code
ourselves rather than letting the macro to generate it for us). We try to figure out
which space the object is in, and invoke trace_object() for the object on that space. If the
object is not in any of the semi spaces in the plan, we forward the call to CommonPlan.
#![allow(unused)] fn main() { impl<VM: VMBinding> Trace for MyGCTrace<VM> { type VM = VM; fn from_mmtk(mmtk: &'static MMTK<Self::VM>) -> Self { // Instantiate `MyGCTrace` from a reference to `MMTK`. // We need to extract the plan reference, and it is sufficient to use downcast. Self { plan: mmtk.get_plan().downcast_ref().unwrap(), } } fn trace_object<Q: crate::ObjectQueue>( &self, worker: &mut crate::scheduler::GCWorker<Self::VM>, object: ObjectReference, queue: &mut Q, ) -> ObjectReference { // We figure out which space the `object` is in, // and call the `trace_object` method of that space. if self.plan.tospace().in_space(object) { self.plan.tospace().trace_object( queue, object, Some(CopySemantics::DefaultCopy), worker, ) } else if self.plan.fromspace().in_space(object) { self.plan.fromspace().trace_object( queue, object, Some(CopySemantics::DefaultCopy), worker, ) } else { // If the `object` is in neither the fromspace nor the tospace, // we delegate to the `CommonPlan`. use crate::plan::PlanTraceObject; use crate::policy::gc_work::DEFAULT_TRACE; self.plan .common .trace_object::<_, DEFAULT_TRACE>(queue, object, worker) } } fn post_scan_object(&self, object: ObjectReference) { // Currently only `ImmixSpace` needs `post_scan_object`. // `CopySpace` does not need the `post_scan_object` method, // so we don't need to call `post_scan_object` on the fromspace or the tospace. // We need to call the `post_scan_object` method of the common plan // because by default the non-moving space is an `ImmixSpace`. use crate::plan::PlanTraceObject; self.plan.common.post_scan_object(object); } fn may_move_objects() -> bool { // We return `true` because SemiSpace moves every single reachable object in the from space. true } } }
In the end, use MyGCTrace as DefaultTrace in the GCWorkContext:
#![allow(unused)] fn main() { pub struct MyGCWorkContext3<VM: VMBinding>(std::marker::PhantomData<VM>); impl<VM: VMBinding> crate::scheduler::GCWorkContext for MyGCWorkContext3<VM> { type VM = VM; type PlanType = MyGC<VM>; type DefaultTrace = MyGCTrace<Self::VM>; type PinningTrace = UnsupportedTrace<Self::VM>; } }
Summary
You should now have MyGC working and able to collect garbage. All three benchmarks should be able to pass now.
If the benchmarks pass - good job! You have built a functional copying collector!
If you get particularly stuck, the code for the completed MyGC plan
is available here.
Exercise: Adding another copyspace
Now that you have a working semispace collector, you should be familiar enough with the code to start writing some yourself. The intention of this exercise is to reinforce the information from the semispace section, rather than to create a useful new collector.
- Create a copy of your semispace collector, called
triplespace. - Add a new copyspace to the collector, called the
youngspace, with the following traits:- New objects are allocated to the youngspace (rather than the fromspace).
- During a collection, live objects in the youngspace are moved to the tospace.
- Garbage is still collected at the same time for all spaces.
Triplespace is a sort of generational garbage collector. These collectors separate out old objects and new objects into separate spaces. Newly allocated objects should be scanned far more often than old objects, which minimises the time spent repeatedly re-scanning long-lived objects.
Of course, this means that the Triplespace is incredibly inefficient for a generational collector, because the older objects are still being scanned every collection. It wouldn't be very useful in a real-life scenario. The next thing to do is to make this collector into a more efficient proper generational collector.
When you are finished, try running the benchmarks and seeing how the performance of this collector compares to MyGC. Great work!
Triplespace backup instructions
This is one possible implementation of the Triplespace collector, provided in case you are stuck on the exercise.
Attempt the exercise yourself before reading this.
First, rename all instances of mygc to triplespace, and add it as a
module by following the instructions in Create MyGC.
In triplespace/global.rs:
-
Add a
youngspacefield topub struct TripleSpace:#![allow(unused)] fn main() { pub struct TripleSpace<VM: VMBinding> { pub hi: AtomicBool, pub copyspace0: CopySpace<VM>, pub copyspace1: CopySpace<VM>, pub youngspace: CopySpace<VM>, // Add this! pub common: CommonPlan<VM>, } } -
Define the parameters for the youngspace in
new()inPlan for TripleSpace:#![allow(unused)] fn main() { fn new( vm_map: &'static VMMap, mmapper: &'static Mmapper, options: Arc<UnsafeOptionsWrapper>, _scheduler: &'static MMTkScheduler<Self::VM>, ) -> Self { //change - again, completely changed. let mut heap = HeapMeta::new(HEAP_START, HEAP_END); TripleSpace { hi: AtomicBool::new(false), copyspace0: CopySpace::new( "copyspace0", false, true, VMRequest::discontiguous(), vm_map, mmapper, &mut heap, ), copyspace1: CopySpace::new( "copyspace1", true, true, VMRequest::discontiguous(), vm_map, mmapper, &mut heap, ), // Add this! youngspace: CopySpace::new( "youngspace", true, true, VMRequest::discontiguous(), vm_map, mmapper, &mut heap, ), common: CommonPlan::new(vm_map, mmapper, options, heap, &TRIPLESPACE_CONSTRAINTS, &[]), } } } -
Initialise the youngspace in
gc_init():#![allow(unused)] fn main() { fn gc_init( &mut self, heap_size: usize, vm_map: &'static VMMap, scheduler: &Arc<MMTkScheduler<VM>>, ) { self.common.gc_init(heap_size, vm_map, scheduler); self.copyspace0.init(&vm_map); self.copyspace1.init(&vm_map); self.youngspace.init(&vm_map); // Add this! } } -
Prepare the youngspace (as a fromspace) in
prepare():#![allow(unused)] fn main() { fn prepare(&self, tls: OpaquePointer) { self.common.prepare(tls, true); self.hi .store(!self.hi.load(Ordering::SeqCst), Ordering::SeqCst); let hi = self.hi.load(Ordering::SeqCst); self.copyspace0.prepare(hi); self.copyspace1.prepare(!hi); self.youngspace.prepare(true); // Add this! } } -
Release the youngspace in
release():#![allow(unused)] fn main() { fn release(&self, tls: OpaquePointer) { self.common.release(tls, true); self.fromspace().release(); self.youngspace().release(); // Add this! } } -
Under the reference functions
tospace()andfromspace(), add a similar reference functionyoungspace():#![allow(unused)] fn main() { pub fn youngspace(&self) -> &CopySpace<VM> { &self.youngspace } }
In mutator.rs:
- Map a bump pointer to the youngspace (replacing the one mapped to the
tospace) in
space_mappingincreate_triplespace_mutator():#![allow(unused)] fn main() { space_mapping: box vec![ (AllocatorSelector::BumpPointer(0), plan.youngspace()), // Change this! ( AllocatorSelector::BumpPointer(1), plan.common.get_immortal(), ), (AllocatorSelector::LargeObject(0), plan.common.get_los()), ], } - Rebind the bump pointer to youngspace (rather than the tospace) in
triplespace_mutator_release():#![allow(unused)] fn main() { pub fn triplespace_mutator_release<VM: VMBinding> ( mutator: &mut Mutator<VM>, _tls: OpaquePointer ) { let bump_allocator = unsafe { mutator .allocators . get_allocator_mut( mutator.config.allocator_mapping[AllocationType::Default] ) } .downcast_mut::<BumpAllocator<VM>>() .unwrap(); bump_allocator.rebind(Some(mutator.plan.youngspace())); // Change this! } }
In gc_work.rs:
- Add the youngspace to trace_object, following the same format as
the tospace and fromspace:
#![allow(unused)] fn main() { fn trace_object(&mut self, object: ObjectReference) -> ObjectReference { // Add this! else if self.plan().youngspace().in_space(object) { self.plan().youngspace.trace_object::<Self, TripleSpaceCopyContext<VM>>( self, object, super::global::ALLOC_TripleSpace, unsafe { self.worker().local::<TripleSpaceCopyContext<VM>>() }, ) } else if self.plan().tospace().in_space(object) { self.plan().tospace().trace_object::<Self, TripleSpaceCopyContext<VM>>( self, object, super::global::ALLOC_TripleSpace, unsafe { self.worker().local::<MyGCCopyContext<VM>>() }, ) } else if self.plan().fromspace().in_space(object) { self.plan().fromspace().trace_object::<Self, MyGCCopyContext<VM>>( self, object, super::global::ALLOC_TripleSpace, unsafe { self.worker().local::<TripleSpaceCopyContext<VM>>() }, ) } else { self.plan().common.trace_object::<Self, TripleSpaceCopyContext<VM>>(self, object) } } } }
Building a generational copying collector
Note: This part is work in progress.
What is a generational collector?
The weak generational hypothesis states that most of the objects allocated
to a heap after one collection will die before the next collection.
Therefore, it is worth separating out 'young' and 'old' objects and only
scanning each as needed, to minimise the number of times old live objects are
scanned. New objects are allocated to a 'nursery', and after one collection
they move to the 'mature' space. In triplespace, youngspace is a
proto-nursery, and the tospace and fromspace are the mature spaces.
This collector fixes one of the major problems with semispace - namely, that any long-lived objects are repeatedly copied back and forth. By separating these objects into a separate 'mature' space, the number of full heap collections needed is greatly reduced.
This section is currently incomplete. Instructions for building a generational copying (gencopy) collector will be added in future.
Further Reading
- MMTk Crate Documentation
- Original MMTk papers:
- Oil and Water? High Performance Garbage Collection in Java with MMTk (Blackburn, Cheng, McKinley, 2004)
- Myths and realities: The performance impact of garbage collection (Blackburn, Cheng, McKinley, 2004)
- The Garbage Collection Handbook (Jones, Hosking, Moss, 2016)
- Videos: MPLR 2020 Keynote, Deconstructing the Garbage-First Collector
Porting Guide
Note: This guide is work in progress.
This guide is designed to get you started on porting MMTk to a new runtime. We start with an overview of the MMTk approach to porting and then step through recommended strategies for implementing a port.
There’s no fixed way to implement a new port. What we outline here is a distillation of best practices that have emerged from community as it has worked through many ports (each at various levels of maturity).
Overview of MMTk’s Approach to Portability
MMTk is designed from the outset to be both high performance and portable. The core of MMTk is entirely runtime-neutral, and is written in Rust. Runtimes that wish to use MMTk may be written in any language so long as they have a means to call into MMTk’s API, which presents itself as a shared library.
MMTk uses the concept of bindings to create high performance impedance matching between runtimes and MMTk.
MMTk’s approach to portability follows these principles:
- The MMTk core must remain entirely runtime-agnostic and free of any runtime-specific code.
- The runtime’s code base should be entirely garbage-collector agnostic and free of any MMTk-specific code.
- The semantics of all MMTk functionality is strictly defined within the MMTk core.
Those principles have the following important implications:
- Each port of a runtime is supported by a binding that has two components: one which is a logical extension of the runtime, written in the same language as the runtime, but which is MMTk-specific, and one which is a logical extension of MMTk, written in Rust, but which is runtime-specific (see diagram below).
- A fully-correct but non-performant port will simply implement calls from the runtime to MMTk (to allocate an object, for example), and from MMTk to the runtime (to enumerate pointers, for example).
- A performant port will likely replicate and lift MMTk functionality into the runtime portion of the port, and conversely replicate runtime functionality in Rust for performant access by MMTk.
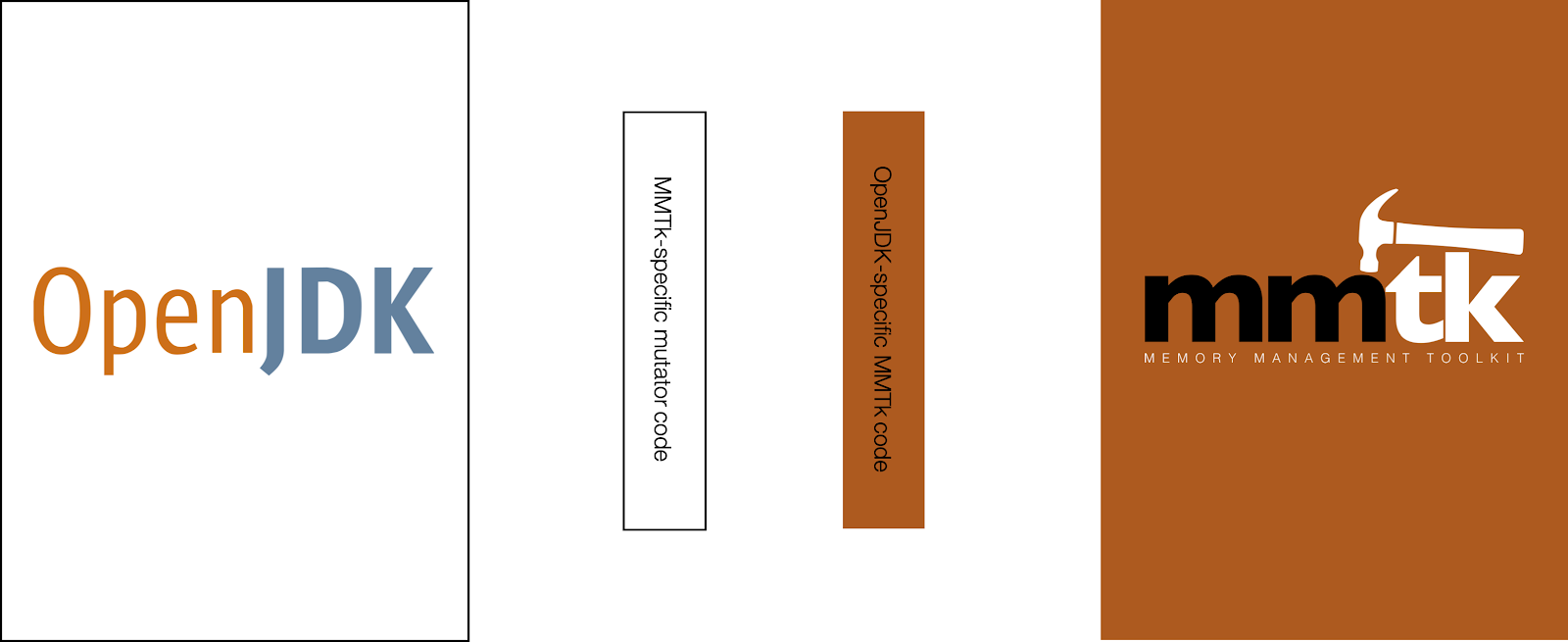
The diagram above illustrates a port of MMTk to OpenJDK with the binding in the center. The code coloured brown is logically part of MMTk and is written in Rust. The code coloured white is logically part of OpenJDK and is written in C++. The rightmost box is entirely free of any OpenJDK-specific code. The leftmost box should be entirely free of any MMTk-specific code.
Note: we do currently maintain a fork of OpenJDK which includes some necessary changes to their code base, but this is not MMTk-specific and ideally this will be upstreamed. Our port to V8 is a cleaner example, where we’ve managed to work closely with the V8 team to upstream all of the refactoring of the V8 code base that was necessary for it to support a third party heap.
We structure the code into three repos. Taking the example of the OpenJDK port, the three repos are: the MMTk core, the binding repo containing both parts of the binding, and the OpenJDK repo, which is currently a fork we maintain.
Things to Consider Before Starting a Port
In principle, a port to MMTk is not particularly difficult. MMTk can present itself as a standard library and the core of the API is relatively simple.
However, porting a runtime to a different GC (any GC) can be difficult and time consuming. Key questions include:
- How well encapsulated is the runtime's existing collector?
- Does the runtime make tacit assumptions about the underlying collector's implementation?
- How many places in the runtime codebase reference some part of the GC?
- If the runtime has a JIT, how good is the interface between the JIT and the GC (for write barriers and allocations, for example)?
- Does the runtime support precise stack scanning?
- etc.
Thinking through these questions should give you a sense for how big a task a GC port will be.
How to Undertake a Port
We recommend a highly incremental approach to implementing a port. The broad idea is:
- Start with the NoGC plan and gradually move to more advanced collectors
- Focus on simplicity and correctness.
- Optimize the port later.
In MMTk’s language, a plan is essentially a configuration which specifies a GC algorithm. Plans can be selected at run time. Not all plans will be suitable for all runtimes. For example, a runtime that for some reason cannot support object movement won’t be able to use plans that use copying garbage collection.
Starting a Port: NoGC
We always start a port with NoGC. It is the simplest possible plan: it simply allocates memory and never collects. Although this appears trivial, depending on the complexity of the runtime and how well factored (or not) its internal GC interfaces are, just getting this working may be a major undertaking. In the case of V8, the refactoring within V8 required to get a simple NoGC plan working was substantial, touching over 100 files. So it’s a good idea not to underestimate the difficulty of a NoGC port!
At a high level, in order to implement NoGC, we need to handle MMTk initialization, mutator initialization, and memory allocation.
If you're ever stuck at any point, feel free to send a message in the #Porting channel of our Zulip!
Set up
You want to set up the binding repository/directory structure before starting the port. For the sake of the tutorial guide we assume you have a directory structure similar to the one below. Note that such a directory structure is not a requirement1 but a recommendation. We assume you are using some form of version control system (such as git or mercurial) in this guide.
mmtk-X/mmtk: The MMTk side of the binding. This includes the implementation of theVMBindingtrait, and any necessary Rust code to integrate MMTk with the VM code (e.g. exposing MMTk functions to native, allowing up-calls from the MMTk binding to the runtime, etc). To start with, you can copy theDummyVMcode and start from there.DummyVMprovides all the Rust boilerplates that you need to implement in the binding side. You can also take a look at one of our officially maintained language bindings as an example: OpenJDK, JikesRVM, V8, Julia, V8.mmtk-X/X: Runtime-specific code for integrating with MMTk. This should act as a bridge between the generic GC interface offered by the runtime and the MMTk side of the binding. This is implemented in the runtime's implementation language. Often this will be one of C or C++.- You can place your runtime repository at any path. For the sake of this guide, we assume you will place the runtime repo as a sibling of the binding repo. You can also clone
mmtk-coreto a local path. Using a local repo ofmmtk-corecan be beneficial to your development in case you need to make certain changes to the core (though this is unlikely).
Your working directory may look like this (assuming your runtime is named as X):
Your working directory/
├─ mmtk-X/
│ ├─ X/
│ └─ mmtk/
├─ X/
└─ mmtk-core/ (optional)
You may also find it helpful to take inspiration from the OpenJDK binding, particularly for a more complete example of the relevant Cargo.toml files.
For this guide, we will assume your runtime is implemented in C or C++ as they are the most common implementation languages. However note that your runtime does not need to be implemented in C/C++ to work with MMTk.
Adding a Rust library to the runtime
We recommend learning the ins and outs of your runtime's build system. You should try and add a simple Rust "hello world" library to your runtime's code and build system to investigate how easy it will be to add MMTk. Unfortunately this step is highly dependent on the runtime build system. We recommend taking a look at what other bindings do, but keep in mind that no two runtime build systems are the same even if they are using the same build tools.
In case the build system is too complex and you want get to hacking, a quick and dirty way to add MMTk could be to build a static and/or dynamic binary for MMTk and link it to the runtime directly, manually building new binaries as necessary, like so:
cd mmtk-X/mmtkcargo buildto build in debug mode or add--releasefor release mode- Copy the shared or static2 library from
target/debugortarget/releaseto your desired location
Later, you can edit the runtime build process to build MMTk at the same time automatically.
Note: If the runtime you are targeting already links some Rust FFI libraries, then you may notice "multiple definition" linker errors for Rust stdlib functions. Unfortunately this is a current limitation of Rust FFI wherein all symbols are bundled together in the final C lib which will cause multiple definitions errors when two or more Rust FFI libraries are linked together. There is ongoing work to stabilize the Rust package format that would hopefully make it easier in the future. A current workaround would be to use the -Wl,--allow-multiple-definition linker flag, but this unfortunately isn't ideal as it increases code sizes. See here and here for more details.
Note: It is highly recommended to also check-in the generated Cargo.lock file into your version control. This improves the reproducibility of the build and ensures the same package versions are used when building in the future in order to prevent random breakages.
We recommend using the debug build when doing development work as it has helpful logging statements and assertions that will make catching bugs in your implementation easier.
The VMBinding trait
Now let's actually start implementing the binding. Here we take a look at the Rust side of the binding first (i.e. mmtk-X/mmtk). What we want to do is implement the VMBinding trait.
The VMBinding trait is a "meta-trait" (i.e. a trait that encapsulates other traits) that we expect every binding to implement. In essence, it is the contract established between MMTk and the runtime. We discuss each of its seven key traits briefly:
ActivePlan: This trait implements functions related to mutators such as how many mutators exist, getting an iterator for all mutators, etc.Collection: This trait implements functions related to garbage collection such as starting and stopping mutators, blocking current mutator thread for GC, etc.ObjectModel: This trait implements the runtime's object model. The object model includes object metadata such as mark-bits, forwarding-bits, etc.; constants regarding assumptions about object addresses; and functions to implement copying objects, querying object sizes, etc. You should carefully implement and understand this as it is a key trait on which many things depend. We will go into more detail about this trait in the object model section.ReferenceGlue: This trait implements runtime-specific finalization and weak reference processing methods. Note that each runtime has its own way of dealing with finalization and reference processing, so this is often one of the trickiest traits to implement.Scanning: This trait implements object scanning functions such as scanning mutator threads for root pointers, scanning a particular object for reference fields, etc.Slot: This trait implements a slot in an object, on the stack or other places (such as global variables). If a slot in your runtime simply holds the address of an object (or 0 for NULL references), you may use theSimpleSlottype. But if your VM uses tagged pointers or compressed pointers, you will need to implement it manually.MemorySlice: This trait implements functions related to memory slices such as arrays. This is mainly used by generational collectors.
For the time-being we can implement all the above traits via unimplemented!() stubs. If you are using the Dummy VM binding as a starting point, you will have to edit some of the concrete implementations to unimplemented!(). Note that you should change the type that implements VMBinding from DummyVM to an appropriately named type for your runtime. For example, the OpenJDK binding defines the zero-struct OpenJDK which implements the VMBinding trait.
Object model
The ObjectModel trait is a fundamental trait describing the layout of an object to MMTk. This is important as MMTk's core doesn't know of how objects look like internally as each runtime will be different. There are certain key aspects you need to be aware of while implementing the ObjectModel trait. We discuss them in this section.
Header vs Side metadata
Per-object metadata can live in one of two places: in the object header or in a separate space used just for metadata. Each one has its pros and cons.
Header metadata sits in close proximity to the actual object address but it is not easy to perform bulk operations. On the other hand, side metadata sits in a dedicated metadata space where each possible object address is assigned some metadata. This makes performing bulk operations easy and does not require stealing bits from the object header (there may in fact be no bits to steal for certain runtimes), but can result in large heap sizes given the metadata space is counted as part of the heap.
The choice of metadata location depends on the runtime and its object model and header layout. For example the JikesRVM runtime reserved extra space at the start of each object for GC-related metadata. Such space may not be available in your runtime. In such cases you can use side metadata to reserve per-object metadata.
Local vs Global metadata
MMTk uses multiple GC policies and each policy may use a different set of object metadata from each other. A moving policy, for example, may require extra metadata (in comparison to a non-moving policy) to store the forwarding bits and forwarding pointer. Such a metadata, which is local to a policy, is referred to as "local" metadata.
However, in certain cases, we may need to have metadata globally for the entire heap space. The classic example is the valid-object bit metadata which tells us if an arbitrary address is allocated/managed by MMTk. Such a metadata, which spans multiple policies, is referred to as "global" metadata.
For example, the Forwarding bits and pointer metadata is a local metadata used by copying policies to store forwarding bits (2-bits) and forwarding pointers (word size). Often runtimes require word-aligned addresses which means we can use the last two bits in the object header (due to alignment) and the entire object header to store the forwarding bits and pointer respectively. This metadata is almost always in the header.
We recommend going through the list of metadata specifications that are defined by MMTk. You should set them to locations that are appropriate for your runtime.
ObjectReference vs Address
A key principle in MMTk is the distinction between ObjectReference and Address. The idea is that very few operations are allowed on an ObjectReference. For example, MMTk does not allow address arithmetic on ObjectReferences. This allows us to preserve memory-safety, only performing unsafe operations when required, and gives us a cleaner and more flexible abstraction to work with as it can allow object handles or offsets etc. Address, on the other hand, represents an arbitrary machine address. You might be interested in reading the Demystifying Magic: High-level Low-level Programming paper which describes the above in more detail.
In MMTk, ObjectReference is a special address that represents an object. It is required to be
within the address range of the object it refers to, and must be word-aligned. This address is used
by MMTk to access side metadata, and find the space or regions (chunk, block, line, etc.) that
contains the object. It must also be efficient to locate the object header (where in-header MMTk
metadata are held) and the object's VM-specific metadata, such as type information, from a given
ObjectReference. MMTk will need to access those information, either directly or indirectly via
traits implemented by the binding, during tracing, which is performance-critical.
The address used as ObjectReference is nominated by the VM binding when an object is allocated (or
moved by a moving GC, which we can ignore for now when supporting NoGC). VMs usually have their own
concepts of "object reference" which refer to objects. Some of them, including OpenJDK and CRuby,
uses addresses to the object (the starting address or at an offset within the object) to refer to an
object. Such VMs can directly use their "object reference" for the address of MMTk's
ObjectReference.
Some VMs, such as JikesRVM, refers to an object by an address at a constant offset after the header,
and can be outside the object. This does not satisfy the requirement of MMTk's ObjectReference,
and the VM binding needs to make a clear distinction between the VM-level object reference and
MMTk's ObjectReference type. A detailed example for supporting such a VM can be found
here.
Other VMs may use tagged references, compressed pointers, etc. They need to convert them to plain
addresses to be used as MMTk's ObjectReference. Specifically, if the VM use such representations
in object fields, the VM binding can deal with the encoding and the decoding in its
Slot implementation, and always present plain ObjectReferences to MMTk. See [this
test] for some Slot implementation examples.
Miscellaneous configuration options
There are many constants in the ObjectModel trait that can be overridden in your binding in order to meet your runtime's requirements. For example, the OBJECT_REF_OFFSET_LOWER_BOUND constant which defines the minimum offset from allocation result start (i.e. the address that MMTk will return to the runtime) and the actual start of the object, i.e. the ObjectReference. In other words, the constant represents the minimum offset from the allocation result start such that the following invariant always holds:
OBJECT_REFERENCE >= ALLOCATION_RESULT_START + OFFSET
We recommend going through the list of constants in the documentation and seeing if the default values suit your runtime's semantics, changing them if required.
MMTk initialization
Now that we have most of the boilerplate set up, the next step is to initialize MMTk so that we can start allocating objects.
In short, MMTk uses the builder pattern. The binding needs to create an MMTKBuilder,
create an MMTK instance from the builder, and then initialize MMTk's collection
when the runtime system is ready for GCs.
The following steps describes details. In an actual binding implementation, the binding may choose to combine several
steps into one function call to make things simpler.
- Create an
MMTKBuilderusingMMTKBuilder::new(). You can set runtime options viaset_option()for things like the GC plan to use, heap sizes, etc. This is a full list of runtime options. You can also set options by directly accessing theoptionsin the builder, such asbuilder.options.threads.set(4). It is a common practice that the VM parses its command line arguments, then sets some GC-related options to MMTk here. You can also set virtual memory layout for MMTk. Some runtimes may require special layouts, such as using compressed pointers with a fixed heap range. However, both setting options and VM layouts are optional -- MMTk will use the default values if none is set. - Create an
MMTKinstance viamemory_manager::mmtk_init(). This enables the binding to use most of the MMTk APIs inmemory_manager, as most APIs require a reference toMMTK. - When the runtime is ready for GCs (including getting its thread system ready to spawn GC threads), it is expected to call
memory_manager::initialize_collection. Once the function returns, MMTk may trigger a GC at any appropriate time. In terms of getting NoGC to work, this step is optional, as NoGC will not trigger GCs.
In practice, it greatly depends on the runtime about how to expose the MMTk's Rust API above to native, and when to call the native API in the runtime.
In the following example, we assume a MMTKBuilder is created statically (Step 1), and expects a call from the runtime to set heap sizes to the builder
via mmtk_set_heap_size(). We will create an MMTK instance from the builder in mmtk_init() (Step 2). Step 3 is omitted, as we do not need it for NoGC.
Runtime-side changes
Create a mmtk.h header file in the runtime folder of the binding (i.e. mmtk-X/X) which exposes the functions required to implement NoGC and #include it in the relevant runtime code. You can use the example mmtk.h header file as an example.
Note: It is convention to prefix all MMTk API functions exposed with mmtk_ in order to avoid name clashes. It is highly recommended that you follow this convention.
Having a clean heap API for MMTk to implement makes life easier. Some runtimes may already have a sufficiently clean abstraction such as OpenJDK after the merging of JEP 304. In (most) other cases, the runtime doesn't provide a clean enough heap API for MMTk to implement. In such cases, it is recommended to create a class (or equivalent) that abstracts allocation and other heap functions. This allows making minimal changes to the actual runtime and having a concrete implementation of the exposed heap API in the binding, reducing MMTk-specific code in the runtime. Ideally these changes are upstreamed.
It is also recommended that any change you do in the runtime be guarded by build-time flags as it helps in maintaining a clean port.
At this step, your mmtk.h file may look something like this:
#ifndef MMTK_H
#define MMTK_H
#include <stddef.h>
#include <sys/types.h>
// The extern "C" is only required if the runtime
// implementation language is C++
extern "C" {
// An arbitrary address
typedef void* Address;
// MmtkMutator should be an opaque pointer for the VM
typedef void* MmtkMutator;
// An opaque pointer to a VMThread
typedef void* VMThread;
/**
* Initialize MMTk instance
*/
void mmtk_init();
/**
* Set the heap size
*
* @param min minimum heap size
* @param max maximum heap size
*/
void mmtk_set_heap_size(size_t min, size_t max);
} // extern "C"
#endif // MMTK_H
Now we can initialize MMTk in the runtime. Note that MMTk should ideally be initialized around when the default heap of the runtime is initialized. You will have to figure out where is the best location to initialize MMTk in your runtime.
Initializing MMTk requires two steps. First, we set the heap size by calling mmtk_set_heap_size with the initial heap size and the maximum heap size. Then, we initialize MMTk by calling mmtk_init. In the future, you may wish to make the heap size configurable via a command line argument or environment variable (See setting options for MMTk).
MMTk-side changes
On the Rust side of the binding, we want to implement the two functions exposed by the mmtk.h file above. We use an MMTKBuilder instance to actually create our concrete MMTK instance. We recommend following the paradigm used by all our bindings wherein we have a static single MMTK instance and an MMTKBuilder instance that we can use to set relevant options. See the OpenJDK binding for an example.
Note: MMTk currently assumes that there is only one MMTK instance in your runtime process. Multiple MMTK instances are currently not supported.
The mmtk_set_heap_size function is fairly straightforward. We recommend using the implementation in the OpenJDK binding. The mmtk_init function is straightforward as well. It should simply manually initialize the MMTK static variable using lazy_static, like here in the OpenJDK binding.
By this point, you should have MMTk initialized. If you are using a debug build (which is recommended) and have logging turned on a message similar to below would be printed out:
[...]
[INFO mmtk::memory_manager] Initialized MMTk with NoGC (FixedHeapSize(10485760))
[...]
Binding mutator threads to MMTk
For MMTk to allocate objects, it needs to be aware of mutator threads. MMTk only allows mutator threads to allocate objects. We do this by "binding" a mutator thread to MMTk when it is initialized in the runtime.
Runtime-side changes
Add the following function to the mmtk.h file:
[...]
/**
* Bind a mutator thread in MMTk
*
* @param tls pointer to mutator thread
* @return an instance of an MMTk mutator
*/
MmtkMutator mmtk_bind_mutator(VMThread tls);
[...]
The mmtk_bind_mutator function takes in an opaque pointer representing an instance of the runtime's mutator thread and returns an opaque pointer to a Mutator instance back to the runtime. The runtime must store this pointer somewhere, preferably in its runtime thread local storage implementation, as MMTk requires a Mutator instance to allocate and perform other actions.
The placement of the mmtk_bind_mutator call in the runtime depends on the runtime's implementation of its thread system. It is recommended to call mmtk_bind_mutator when the runtime initializes the thread local storage of a newly created thread. This ensures that the thread can allocate from MMTk immediately after initialization.
MMTk-side changes
The Rust side of the binding should simply defer the actual implementation to mmtk::memory_manager::bind_mutator. See the OpenJDK binding for an example.
Allocation
Now we can finally implement the allocation functions.
Runtime-side changes
Add the following two functions to the mmtk.h file:
[...]
/**
* Allocate an object
*
* @param mutator the mutator instance that is requesting the allocation
* @param size the size of the requested object
* @param align the alignment requirement for the object
* @param offset the allocation offset for the object
* @param allocator the allocation semantics to use for the allocation
* @return the address of the newly allocated object
*/
void *mmtk_alloc(MmtkMutator mutator, size_t size, size_t align,
ssize_t offset, int allocator);
/**
* Set relevant object metadata
*
* @param mutator the mutator instance that is requesting the allocation
* @param object the ObjectReference address chosen by the VM binding
* @param size the size of the allocated object
* @param allocator the allocation semantics to use for the allocation
*/
void mmtk_post_alloc(MmtkMutator mutator, void* object, size_t size, int allocator);
[...]
In order to perform allocations, you will need to know what object alignment the runtime expects. Runtimes often align allocations at word boundaries (i.e. 4- or 8-bytes) as it allows the CPU to access the data faster at execution time. Additionally, the runtime may use the unused lowest order bits to store flags (e.g. type information), so it is important that MMTk respects these expectations. Once you have figured out the alignment requirements for your runtime, you should update the MIN_ALIGNMENT constant in VMBinding to the correct value.
Now that MMTk is aware of each mutator thread, you have to change the runtime's allocation functions to call into MMTk to allocate using mmtk_alloc and set object metadata using mmtk_post_alloc. Note that there may be multiple allocation functions in the runtime so make sure that you edit them all!
When calling mmtk_alloc, you should use the saved Mutator pointer as the first parameter, the requested object size as the next parameter, and any alignment requirements the runtimes has as the third parameter.
If your runtime requires a non-zero allocation offset (i.e. the alignment requirements are for the offset address, not the returned address) then you have to provide the required value as the fourth parameter. Note that you must also update the USE_ALLOCATION_OFFSET constant in the VMBinding implementation if your runtime requires a non-zero allocation offset.
For the time-being, you can ignore the allocator parameter in both these functions and always pass a value of 0 which means MMTk will pick the default allocator for your collector (a bump pointer allocator in the case of NoGC).
The return value of mmtk_alloc is the starting address of the allocated object.
Then you should nominate a word-aligned address within the allocated bytes to be the
ObjectReference used to refer to that object from now on. It doesn't have to be the starting
address.
Finally, you need to call mmtk_post_alloc with your chosen ObjectReference in order to
initialize MMTk-level object metadata, such as logging bits, valid-object (VO) bits, etc. As a VM
binding developer, you can ignore the details for now.
Note: Currently MMTk assumes object sizes are multiples of the MIN_ALIGNMENT. If you encounter errors with alignment, a simple workaround would be to align the requested object size up to the MIN_ALIGNMENT. See here for the tracking issue to fix this bug.
MMTk-side changes
The Rust side of the binding should simply defer the actual implementation to mmtk::memory_manager::alloc and mmtk::memory_manager::post_alloc respectively. See the OpenJDK binding for an example.
Congratulations! At this point, you hopefully have object allocation working and can run simple programs with your runtime using MMTk!
Miscellaneous implementation steps
Setting options for MMTk
The preferred method of setting options for MMTk is by setting them via the MMTKBuilder instance. See here for an example in the OpenJDK binding.
The process function can also be used to pass options. You may want to set multiple options at the same time. In such a case you can use the process_bulk function.
MMTk also supports setting options via environment variables. This is generally only recommended at early stages of the porting process in order for quick development. For example, to use the NoGC plan, you can set the environment variable MMTK_PLAN=NoGC.
A full list of available options that you can set can be found here.
Runtime-specific steps
Often it is the case that the above changes are not enough to allow a runtime to work with MMTk. For example, for the ART binding, the runtime required that all inflated locks be deflated prior to writing the boot image. In order to fix this, we had to implement a heap visitor that visited each allocated object and checked if it had inflated locks, deflating them if they were.
Unfortunately there is no real magic bullet here. If you come across a runtime-specific idiosyncrasy (and you almost certainly will), you will have to understand what the underlying bug is and either fix or work around it.
If you have any confusions or questions, please free to reach us on our Zulip! We would be glad to help.
-
In fact some bindings may not be able to have such a directory structure due to the build tools used by the runtime. ↩
-
You would have to change the
crate-typeinmmtk-X/mmtk/Cargo.tomlfromcdylibtostaticlibto build a static library. ↩
Next Steps
Your choice of the next GC plan to implement depends on your situation. If you’re developing a new VM from scratch, or if you are intimately familiar with the internals of your target VM, then implementing a SemiSpace collector is probably the best course of action. Although the GC itself is rather simplistic, it stresses many of the key components of the MMTk <-> VM binding that will be required for later (and more powerful) GCs. In particular, since it always moves objects, it is an excellent stress test.
An alternative route is to implement MarkSweep. This may be necessary in scenarios where the target VM doesn’t support object movement, or would require significant refactoring to do so. This can then serve as a stepping stone for future, moving GCs such as SemiSpace.
We hope to have an Immix implementation available soon, which provides a nice middle ground between moving and non-moving (since it copies opportunistically, and can cope with a strictly non-moving requirement if needs be).
Debugging Tips
In this section, we discuss debugging tips that will be useful to debug MMTk in a binding implementation. We will focus on discussing strategies and tools in the specific context of debugging MMTk.
We aim to enhance the debugging capabilities for MMTk. However, as of October 2023, our debugging tools remain limited. We welcome your feedback and suggestions. If there's a specific debugging tool you'd like to see or have recommendations, please reach out to us on Zulip or submit your thoughts via issues.
Enable debug assertions
MMTk is implemented with an extensive amount of assertions to ensure the correctness.
We strongly recommend using a debug build of MMTk that includes all the debugging assertions
when one is developing on a MMTk binding. The assertions are normal Rust debug_assert!,
and they can be turned on in a release build with Rust flags (https://doc.rust-lang.org/cargo/reference/profiles.html#debug-assertions).
Extreme debugging assertions
In addition to the normal debugging assertions, MMTk also has a set of
optional runtime checks that can be turned on by enabling the feature extreme_assertions.
These usually include checks that are too expensive (even in a debug build) that we do not
want to enable by default.
You should make sure your MMTk binding can pass all the assertions (including extreme_assertions).
Print MMTk Object Information
MMTk provides a utility function to print object information for debugging, crate::mmtk::mmtk_debug_print_object.
The function is marked as #[no_mangle], making it suitable to be used in a debugger.
The following example shows how to use the function to print MMTk's object metadata before and after a single GC in rr.
Set up break points before and after a GC.
(rr) b stop_all_mutators
Breakpoint 1 at 0x767cba8f74e8 (14 locations)
(rr) b resume_mutators
Breakpoint 2 at 0x767cba8f8908
When the program stops, call mmtk_debug_print_object. We might need to
set the language context in the debugger to C when we stop in a Rust frame.
Then call mmtk_debug_print_object with the interested object.
(rr) set language c
(rr) call mmtk_debug_print_object(0x200fffed9f0)
In immix:
marked = false
line marked = false
block state = Unmarked
forwarding bits = 0, forwarding pointer = None
vo bit = true
Debugging Copying in Immix Plans
Immix uses opportunitic copying, which means it does not always copy objects. So a bug related with copying may be non-deterministic with Immix plans.
One way to make copying more deterministic is to use the following options to change the copying behavior of Immix.
| Option | Default Value | Note |
|---|---|---|
immix_always_defrag | false | Immix only does defrag GC when necessary. Set to true to make every GC a defrag GC |
immix_defrag_every_block | false | Immix only defrags the most heavily fragmented blocks. Set to true to make Immix defrag every block with equal chances |
immix_defrag_headroom_percent | 2 | Immix uses 2% of the heap for defraging. We can reserve more headroom to copy more objects. 50% makes Immix behave like SemiSpace. |
A common way to maximumally expose Immix copying bugs is to run with the following values:
#![allow(unused)] fn main() { // Set options with MMTkBuilder builder.options.immix_always_defrag.set(true); builder.options.immix_defrag_every_block.set(true); builder.options.immix_defrag_headroom_percent.set(50); }
These options can also be used along with stress GC options:
#![allow(unused)] fn main() { // Do a stress GC for every 10MB allocation builder.options.stress_factor.set(10485760); }
Options can also be set using environment variables.
export MMTK_IMMIX_ALWAYS_DEFRAG=true
export MMTK_IMMIX_DEFRAG_EVERY_BLOCK=true
export MMTK_IMMIX_DEFRAG_HEADROOM_PERCENT=50
export MMTK_STRESS_FACTOR=10485760
Traverse Object Graph with a Debugger
Tracing through an object graph with a debugger can be tricky in MMTk. Garbage collection in MMTk is executed in units called work packets. These include packets that trace slots and packets that scan objects. When scanning an object, MMTk may not carry context about the slot from which the object reference was loaded.
This section demonstrates how to use rr to traverse the object graph.
Suppose a program segfaults during GC while scanning a corrupted object (e.g. 0x725a62eb60f0). Our goal is to determine:
- Which slot loaded this object reference.
- Which object that slot belongs to.
Note: Traversing the entire object graph is rarely the best debugging strategy. Graphs can be large, and resolving object → slot → object → slot → … repeatedly is time-consuming and error-prone. Prefer simpler approaches if possible. Object-graph reversal should be considered a last resort.
Step 1: Set Breakpoints at GC Boundaries
First, replay the execution to the point of the segfault. Then, to ensure you know which GC cycle you’re in, set breakpoints at the start and end of each GC:
(rr) b stop_all_mutators
(rr) b resume_mutators
These breakpoints help you detect if replay takes you into a different GC than the one that crashed.
Step 2: Identify the Slot that Loaded the Object
Object references are usually loaded from slots in
ProcessSlots::process_slots.
The current code looks like this:
#![allow(unused)] fn main() { fn process_slots( &mut self, worker: &mut GCWorker<T::VM>, trace: T, ) -> VectorQueue<ObjectReference> { let mut queue = VectorObjectQueue::new(); for slot in self.slots.iter() { if let Some(object) = slot.load() { let new_object = trace.trace_object(worker, object, &mut queue); if T::may_move_objects() && new_object != object { slot.store(new_object); } } } queue } }
At the slot.load() / trace.trace_object(...) point, object is the reference of interest.
To catch the corrupted object (0x725a62eb60f0), set a conditional breakpoint there.
Conditions can be expressed in different ways, such as if object.as_raw_address().as_usize() == 0x725a62eb60f0 (Rust),
if (uintptr_t)object == 0x725a62eb60f0 (C), and if $rsi == 0x725a62eb60f0.
Using registers seems to work more reliably when
the execution keeps switching between Rust and C. You can find which register holds the value 0x725a62eb60f0 (using info registers)
and use that as the condition. If the value 0x725a62eb60f0 does not appear in any register, you can step forward through one or more statements,
until you see the value appears. Set the breakpoint at that line.
Automating with a Temporary Breakpoint
Since we only need the breakpoint once, a temporary breakpoint is convenient. We can also set up a GDB command, as we will likely do this step repeatedly to traverse the object.
Define a helper GDB command. You need to change the example below to match your recorded trace:
- The file path.
- The line number inside
ProcessSlots::process_slots. - The register that holds the value
object.
(rr) define find_slot
>tbreak /path/to/mmtk-core/src/plan/tracing/gc_work/closure.rs:41 if $rsi == $arg0
>reverse-cont
>end
Usage:
(rr) find_slot 0x725a62eb60f0
Temporary breakpoint 1 at 0x...: /path/to/mmtk-core/src/plan/tracing/gc_work/closure.rs:41. (N locations)
If the breakpoint hits (it may take a while), you’ll see something like:
Thread 2 hit Temporary breakpoint 1, mmtk::plan::tracing::gc_work::closure::ProcessSlots<...>::process_slots (...) at /path/to/mmtk-core/src/plan/tracing/gc_work/closure.rs:41
41 let new_object = trace.trace_object(worker, object, &mut queue);
Then:
(rr) p/x slot
$2 = mmtk_julia::slots::JuliaVMSlot::Simple(mmtk::vm::slot::SimpleSlot {slot_addr: 0x725a62eb6168})
Here we learn that object 0x725a62eb60f0 was loaded from slot 0x725a62eb6168.
If instead you hit stop_all_mutators, it means the object was not processed through
ProcessSlots (our conditional breakpoint) in this GC. Similar techniques apply: set breakpoints
in other relevant paths until you find where the object comes from.
Step 3: Identify the Object that Owns the Slot
Now that we know slot 0x725a62eb6168 contains the object 0x725a62eb60f0, we need to determine which object this slot belongs to.
Slots are reported when bindings scan an object via
Scanning::scan_object,
which calls SlotVisitor::visit_slot
for each outgoing reference field.
To find the owning object, set a conditional breakpoint in mmtk-core at the SlotVisitor
implementation for closures.
Define another helper command:
(rr) define find_object
>tbreak /path/to/mmtk-core/src/vm/scanning.rs:16 if $rsi == $arg0
>reverse-cont
>end
Usage:
(rr) find_object 0x725a62eb6168
Temporary breakpoint 2 at 0x...: /path/to/mmtk-core/src/vm/scanning.rs:16. (N locations)
When the breakpoint hits:
Thread 2 hit Temporary breakpoint 2, <... as mmtk::vm::scanning::SlotVisitor<...>>::visit_slot (...) at /path/to/mmtk-core/src/vm/scanning.rs:16
16 self(slot)
From the stack, you can walk upward to find the object that is being scanned.
(rr) up
#1 ... in <closure at ...>
(rr) up
#2 ... in <your binding>::scan_object(...)
(rr) up
#3 ... in mmtk::plan::tracing::gc_work::closure::ProcessNodes<...>::try_enqueue_slots(...)
(rr) p/x obj
$1 = mmtk::util::address::Address (0x725a62eb6130)
By repeating Step 2 (finding the slot that loaded an object) and Step 3 (finding the object that owns that slot), you can walk backward through the object graph. Continue this process until you reach a point of interest -- such as the root object, or an object that erroneously enqueues a slot.
Performance Tuning for Bindings
In this section, we discuss how to achieve the best performance with MMTk in a binding implementation. MMTk is a high performance GC library. But there are some key points that need to be done correctly to achieve the optimal performance.
Enabling Link Time Optimization (LTO) with MMTk
MMTk's API is designed with an assumption that LTO will be enabled for a performant build.
It is essential to allow the Rust compiler to optimize across the crate boundary between the binding crate and mmtk-core.
LTO allows inlining for both directions (from mmtk-core to the binding, and from the binding to mmtk-core),
and allows further optimization such as specializing and constant folding for the VMBinding trait.
We suggest enabling LTO for the release build in the binding's manifest (Cargo.toml) by adding a profile for the release build,
so LTO is always enabled for a release build.
[profile.release]
lto = true
If your binding project is a Rust binary (e.g. the VM is written in Rust), this should be enough. However, if your binding project is a library, there are some limitations with cargo that you should be aware of.
Binding as a library
Cargo only allows LTO for certain crate types. You will need to specify the crate type properly, otherwise cargo may skip LTO without any warning or error.
[lib]
...
# be careful - LTO is only allowed for certain crate types
crate-type = ["cdylib"]
At the time of writing, cargo has some limitations about LTO with different crate types:
- LTO is only allowed with
cdylibandstaticlib(other thanbin). Check the code ofcan_ltofor your Rust version to clarify. - If the
crate-typefield includes any type that LTO is not allowed, LTO will be skipped for all the libraries generated (https://github.com/rust-lang/rust/issues/51009). For example, if you havecrate-type = ["cdylib", "rlib"]and cargo cannot do LTO forrlib, LTO will be skipped forcdylibas well. So only keep the crate type that you actually need in thecrate-typefield.
Optimizing Allocation
MMTk provides alloc()
and post_alloc(), to allocate a piece of memory, and
finalize the memory as an object. Calling them is sufficient for a functional implementation, and we recommend doing
so in the early development of an MMTk integration. However, as allocation is performance critical, runtimes generally would want to
optimize allocation to make it as fast as possible, in which invoking alloc() and post_alloc() becomes inadequate.
The following discusses a few design decisions and optimizations related to allocation. The discussion mainly focuses on alloc().
post_alloc() works in a similar way, and the discussion can also be applied to post_alloc().
For concrete examples, you can refer to any of our supported bindings, and check the implementation in the bindings.
Note: Some of the optimizations need to make assumptions about MMTk's internal implementation and may make the code less maintainable. We recommend adding assertions in the binding code to make sure the assumptions are not broken across versions.
Efficient access to MMTk mutators
An MMTk mutator context (created by bind_mutator()) is a thread-local data structure
of type Mutator.
MMTk expects the binding to provide efficient access to the mutator structure in their thread-local storage (TLS).
Usually one of the following approaches is used to store MMTk mutators.
Option 1: Storing the pointer
The Box<Mutator<VM>> returned from mmtk::memory_manager::bind_mutator is actually a pointer to
a Mutator<VM> instance allocated in the Rust heap. It is simple to store it in the TLS.
This approach does not make any assumption about the internals of an MMTk Mutator. However, it requires an extra pointer dereference
when accessing a value in the mutator. This may sound not too bad, however, this degrades the performance of
a carefully implemented inlined fast-path allocation sequence which is normally just a few (assembly) instructions.
This approach could be a simple start in early development, but we do not recommend it for an efficient implementation.
If the VM is not implemented in Rust, the binding needs to turn the boxed pointer into a raw pointer before storing it.
#![allow(unused)] fn main() { struct MutatorInTLS { // Store the mutator as a boxed pointer. // Accessing any value in the mutator will need a dereferencing of the boxed pointer. ptr: Box<Mutator<MockVM>>, } // Bind an MMTk mutator let mutator = memory_manager::bind_mutator(fixture.get_mmtk(), tls_opaque_pointer); // Store the pointer in TLS let mut storage = MutatorInTLS { ptr: mutator }; // Allocate let addr = memory_manager::alloc(&mut storage.ptr, 8, 8, 0, AllocationSemantics::Default); }
Option 2: Embed the Mutator struct
To remove the extra pointer dereference, the binding can embed the Mutator type into their TLS type. This saves the extra dereference.
If the implementation language is not Rust, the developer needs to create a type that has the same layout as Mutator. It is recommended to
have an assertion to ensure that the native type has the exact same layout as the Rust type Mutator.
#![allow(unused)] fn main() { struct MutatorInTLS { embed: Mutator<MockVM>, } // Bind an MMTk mutator let mutator = memory_manager::bind_mutator(fixture.get_mmtk(), tls_opaque_pointer); // Store the struct (or use memcpy for non-Rust code) let mut storage = MutatorInTLS { embed: *mutator }; // Allocate let addr = memory_manager::alloc( &mut storage.embed, 8, 8, 0, AllocationSemantics::Default, ); }
Option 3: Embed the fast-path struct
The size of Mutator is a few hundreds of bytes, which could be considered too large to store in the TLS in some language implementations.
Embedding Mutator also requires to duplicate a native type for the Mutator struct if the implementation language is not Rust.
Sometimes it is undesirable to embed the Mutator type. One can choose to only embed the fast-path struct that is in use.
Unlike the Mutator type, the fast-path struct has a C-compatible layout, and it is simple and primitive enough
so it is unlikely to change. For example, MMTk provides BumpPointer,
which simply includes a cursor and a limit.
In the following example, we embed one BumpPointer struct in the TLS.
The BumpPointer is used in the fast-path, and carefully synchronized with the allocator in the Mutator struct in the slow-path. We also need to revoke (i.e. reset) all the cached BumpPointer values for all mutators if a GC occurs. Currently, we recommend implementing this in the resume_mutators API call, however there is work in progress that would make it an explicit API call instead.
Note that the allocate_default closure in the example below assumes the allocation semantics is AllocationSemantics::Default
and its selected allocator uses bump-pointer allocation.
Real-world fast-path implementations for high-performance VMs are usually JIT-compiled, inlined, and specialized for the current plan
and allocation site. Hence, the allocation semantics of the concrete allocation site (and therefore the selected allocator) is known to the JIT compiler.
For the sake of simplicity, we only store one BumpPointer in the TLS in the example.
In MMTk, each plan has multiple allocators, and the allocation semantics are mapped
to those allocator by the GC plan you choose. So a plan uses multiple allocators, and
depending on how many allocation semantics are used by a binding, the binding may use multiple allocators as well.
In practice, a binding may embed multiple fast-path structs for all the allocators they use if they would like
more efficient allocation.
Also for simplicity, the example assumes the default allocator for the plan in use is a bump pointer allocator.
Many plans in MMTk use bump pointer allocator for their default allocation semantics (AllocationSemantics::Default),
which includes (but not limited to) NoGC, SemiSpace, Immix, generational plans, etc.
If a plan does not do bump-pointer allocation, we may still implement fast-paths, but we need to embed different data structures instead of BumpPointer.
#![allow(unused)] fn main() { use crate::util::alloc::BumpPointer; struct MutatorInTLS { default_bump_pointer: BumpPointer, mutator: Box<Mutator<MockVM>>, } // Bind an MMTk mutator let mutator = memory_manager::bind_mutator(fixture.get_mmtk(), tls_opaque_pointer); // Create a fastpath BumpPointer with default(). The BumpPointer from default() will guarantee to fail on the first allocation // so the allocation goes to the slowpath and we will get an allocation buffer from MMTk. let default_bump_pointer = BumpPointer::default(); // Store the fastpath BumpPointer along with the mutator let mut storage = MutatorInTLS { default_bump_pointer, mutator, }; // Allocate let mut allocate_default = |size: usize| -> Address { // Alignment code is omitted here to make the code simpler to read. // In an actual implementation, alignment and offset need to be considered by the bindings. let new_cursor = storage.default_bump_pointer.cursor + size; if new_cursor < storage.default_bump_pointer.limit { let addr = storage.default_bump_pointer.cursor; storage.default_bump_pointer.cursor = new_cursor; addr } else { use crate::util::alloc::Allocator; let selector = memory_manager::get_allocator_mapping( fixture.get_mmtk(), AllocationSemantics::Default, ); let default_allocator = unsafe { storage .mutator .allocator_impl_mut::<crate::util::alloc::BumpAllocator<MockVM>>( selector, ) }; // Copy bump pointer values to the allocator in the mutator default_allocator.bump_pointer = storage.default_bump_pointer; // Do slow path allocation with MMTk let addr = default_allocator.alloc_slow(size, 8, 0); // Copy bump pointer values to the fastpath BumpPointer so we will have an allocation buffer. storage.default_bump_pointer = default_allocator.bump_pointer; addr } }; // Allocate: this will fail in the fastpath, and will get an allocation buffer from the slowpath let addr1 = allocate_default(8); // Allocate: this will allocate from the fastpath let addr2 = allocate_default(8); }
And pseudo-code for how you would reset the BumpPointers for all mutators in resume_mutators. Note that these mutators are the runtime's actual mutator threads (i.e. where the cached bump pointers are stored) and are different from MMTk's Mutator struct.
#![allow(unused)] fn main() { impl Collection<RtName> for RtNameCollection { ... fn resume_mutators(tls: VMWorkerThread) { // Reset the cached bump pointers of each mutator (setting both cursor and limit to 0) after a GC to // ensure that the VM sees a cohesive state for mutator in mutators { mutator.storage.default_bump_pointer = BumpPointer::default(); } // Actually resume all the mutators now ... } ... } }
Avoid resolving the allocator at run time
For a simple and general API of alloc(), MMTk requires AllocationSemantics as an argument in an allocation request, and resolves it at run-time.
The following is roughly what alloc() does internally.
- Resolving the allocator
- Find the
Allocatorfor the requiredAllocationSemantics. It is defined by the plan in use. - Dynamically dispatch the call to
Allocator::alloc().
- Find the
Allocator::alloc()executes the allocation fast-path.- If the fast-path fails, it executes the allocation slow-path
Allocator::alloc_slow(). - The slow-path will further attempt to allocate memory, and may trigger a GC.
Resolving to a specific allocator and doing dynamic dispatch is expensive for an allocation. With the build-time or JIT-time knowledge about the object that will be allocated, an MMTk binding can possibly skip the first step in the run time.
If you implement an efficient fast-path allocation in the binding side (like the Option 3 above, and generating allocation code in a JIT), that naturally avoids this problem. If you do not want to implement the fast-path allocation, the following is another example of how to avoid resolving the allocator.
Once MMTk is initialized, a binding can get the memory offset for the default allocator, and save it somewhere. When we know an object should be allocated with the default allocation semantics, we can use the offset to get a reference to the actual allocator (with unsafe code), and allocate with the allocator.
#![allow(unused)] fn main() { // At boot time let selector = memory_manager::get_allocator_mapping( fixture.get_mmtk(), AllocationSemantics::Default, ); let default_allocator_offset = crate::plan::Mutator::<MockVM>::get_allocator_base_offset(selector); let mutator = memory_manager::bind_mutator(fixture.get_mmtk(), tls_opaque_pointer); // At run time: allocate with the default semantics without resolving allocator let default_allocator: &mut BumpAllocator<MockVM> = { let mutator_addr = Address::from_ref(&*mutator); unsafe { (mutator_addr + default_allocator_offset).as_mut_ref::<BumpAllocator<MockVM>>() } }; let addr = default_allocator.alloc(8, 8, 0); }
Emitting Allocation Sequence in a JIT Compiler
If the language has a JIT compiler, it is generally desirable to generate the code sequence for the allocation fast-path, rather than simply emitting a call instruction to the allocation function. The optimizations we talked above are relevant as well: (i) the compiler needs to be able to access the mutator, and (ii) the compiler needs to be able to resolve to a specific allocator at JIT time. The actual implementation highly depends on the compiler implementation.
The following are some examples from our bindings (at the time of writing):
VM-specific Concerns
Every VM is special in some way. Because of this, some VM bindings may use MMTk features not usually used by most VMs, and may even deviate from the usual steps of integrating MMTk into the VM. Here we provide special guides to cover such cases.
Finalizers and Weak References
Some VMs support finalizers, weak references, and other complex data structures that have weak reference semantics, such as weak tables (hash tables where the key, the value or both can be weak references), ephemerons, etc. The concrete semantics of finalizer and weak reference varies from VM to VM, but MMTk provides a low-level API that allows the VM bindings to implement their flavors of finalizer and weak references on top of it.
Definitions
In this chapter, we use the following definitions. They may be different from the definitions in concrete VMs.
Finalizers are clean-up operations associated with an object, and are executed when the garbage collector determines the object is no longer reachable. Depending on the VM, finalizers may have different properties.
- Finalizers may be executed immediately during GC, or postponed to mutator time.
- They may have access to the object body, or executed independently from the object.
- They may "resurrect" the unreachable object, or guarantee unreachable objects remain unreachable after finalization.
Weak references are special object graph edges distinct from ordinary "strong" references.
- An object is strongly reachable if there is a path from roots to the object that contains only strong references.
- An object is weakly reachable if any path from the roots to the object must contain at least one weak reference.
The garbage collector may reclaim weakly reachable objects, clear weak references to weakly reachable objects, and/or perform associated clean-up operations.
A note for Java programmers: In Java, the term "weak reference" often refers to instances of
java.lang.ref.Reference (including the concrete classes SoftReference, WeakReference,
PhantomReference and the hidden FinalizerReference class used by some JVM implementations to
implement finalizers). Instances of Reference are proper Java heap objects, but each instance has
a field that contains a pointer to the referent, and the field can be cleared when the referent
dies. In this article, we use the term "weak reference" to refer to the pointer inside that field.
In other words, a Java Reference instance has a field that holds a weak reference to the referent.
Overview of MMTk's finalizer and weak reference processing API
During each GC, MMTk core starts tracing from roots. It will follow strong references discovered by
Scanning::scan_object and Scanning::scan_object_and_trace_edges. After all strongly reachable
objects have been reached (i.e. the transitive closure including strongly reachable objects is
computed), MMTk will call Scanning::process_weak_refs which is implemented by the VM binding.
Inside this function, the VM binding can do several things.
- Query reachability: The VM binding can query whether any given object has been reached.
- Do this with
ObjectReference::is_reachable().
- Do this with
- Query forwarded address: If an object has already been reached, the VM binding can further
query the new address of an object. This is needed to support copying GC.
- Do this with
ObjectReference::get_forwarded_object().
- Do this with
- Retain objects: If an object has not been reached at this time, the VM binding can
optionally demand the object to be retained. That object and all descendants will be kept
alive during this GC.
- Do this with the
tracer_contextargument ofprocess_weak_refs.
- Do this with the
- Request another invocation: The VM binding can request
Scanning::process_weak_refsto be called again after computing the transitive closure that includes retained objects and their descendants. This helps handling multiple levels of weak reference strength.- Do this by returning
truefromprocess_weak_refs.
- Do this by returning
The Scanning::process_weak_refs function also gives the VM binding a chance to perform other
operations, including (but not limited to)
- Do clean-up operations: The VM binding can perform clean-up operations, or queue them to be executed after GC.
- Update fields that contain weak references.
- Forward the field: It can write the forwarded address of the referent if moved by a copying GC.
- Clear the field: It can clear the field if the referent has not been reached and the binding decides it is unreachable.
Using those primitive operations, the VM binding can support different flavors of finalizers and/or weak references. We will discuss common use cases in the following sections.
Supporting finalizers
Different languages and VMs define "finalizer" differently, but they all involve performing operations when an object is dead. The general way to handle finalizer is visiting all finalizable objects (i.e. objects that have associated finalization operations), check if they are unreachable and, if unreachable, do something about them.
Identifying finalizable objects
Some VMs determine whether an object is finalizable by its type. In Java, for example, an object is
finalizable if its finalize() method is overridden. The VM binding can maintain a list of
finalizable objects, and register instances of such types into that list when they are constructed.
Some VMs can dynamically attach finalizing operations to individual objects after objects are created. The VM binding can maintain a list of objects with attached finalizers, or maintain a (weak) hash map that maps finalizable objects to its associated finalizers.
When to run finalizers?
Depending on the finalizer semantics in different VMs, finalizers can be executed during GC or during mutator time after GC.
The VM binding can run finalizers immediately in Scanning::process_weak_refs when finding a
finalizable object unreachable. Beware that executing finalizers can be time-consuming. The VM
binding can creating work packets and let each work packet process a part of all finalizable
objects. In this way, multiple GC workers can process finalizable objects in parallel. The
Scanning::process_weak_refs function is executed in the VMRefClosure stage, so the created work
packets shall be added to the same bucket.
If the finalizers should be executed after GC, the VM binding should enqueue such jobs to VM-specific queues so that they can be picked up by mutator threads after GC.
Reading the body of dead object
In some VMs, finalizers can read the fields in dead objects. Such fields usually include information needed for cleaning up resources held by the object, such as file descriptors and pointers to memory not managed by GC.
Scanning::process_weak_refs is executed in the VMRefClosure stage, which happens after computing
transitive closure, but before any object has been released (which happens in the Release stage).
This means the body of all objects, live or dead, can still be accessed during this stage.
Therefore, there is no problem reading the object body if the VM binding executes finalizers
immediately in process_weak_refs, or in created work packets in the VMRefClosure stage.
However, if the VM needs to execute finalizers after GC, it will be a problem because the object will have been reclaimed, and memory of the object will have been overwritten by other objects. In this case, the VM will need to retain the dead object to make it accessible after the current GC.
Retaining unreachable objects
Some VMs, particularly the Java VM, executes finalizers during mutator time. Any finalizable objects unreachable before a GC must be retained so that they can still be accessed by their finalizers after the GC.
The Scanning::process_weak_refs has an parameter tracer_context: impl ObjectTracerContext<VM>.
This parameter provides the necessary mechanism to retain objects and make them (and their
descendants) live through the current GC. The typical use pattern is:
#![allow(unused)] fn main() { impl Scanning<MyVM> for VMScanning { fn process_weak_refs( worker: &mut GCWorker<MyVM>, tracer_context: impl ObjectTracerContext<MyVM>, ) -> bool { let finalizable_objects: Vec<ObjectReference> = my_vm::get_finalizable_object(); let mut new_finalizable_objects = vec![]; tracer_context.with_tracer(worker, |tracer| { for object in finalizable_objects { if object.is_reachable() { // `object` is still reachable. // It may have been moved if it is a copying GC. let new_object = object.get_forwarded_object().unwrap_or(object); new_finalizable_objects.push(new_object); } else { // `object` is unreachable. // Retain it, and enqueue it for postponed finalization. let new_object = tracer.trace_object(object); my_vm::enqueue_finalizable_object_to_be_executed_later(new_object); } } }); my_vm::set_new_finalizable_objects(new_finalizable_objects); false } // ... }
Within the closure |tracer| { ... }, the VM binding can call tracer.trace_object(object) to
retain object. It returns the new address of object because in a copying GC the trace_object
function can also move the object.
Under the hood, tracer_context.with_tracer creates a queue and calls the closure. The tracer
implements the ObjectTracer trait, and is just an interface that provides the trace_object
method. Objects retained by tracer.trace_object will be enqueued. After the closure returns,
with_tracer will split the queue into reasonably-sized work packets and add them to the
VMRefClosure work bucket. Those work packets will trace the retained objects and their
descendants, effectively expanding the transitive closure to include all objects reachable from the
retained objects. Because of the overhead of creating queues and work packets, the VM binding
should retain as many objects as needed in one invocation of with_tracer, and avoid calling
with_tracer again and again for each object.
Don't do this:
#![allow(unused)] fn main() { for object in objects { tracer_context.with_tracer(worker, |tracer| { // This is expensive! DON'T DO THIS! tracer.trace_object(object); }); } }
Keep in mind that tracer_context implements the Clone trait. As introduced in the When to
run finalizers section, the VM binding can use work packets to
parallelize finalizer processing. If finalizable objects need to be retained, the VM binding can
clone the trace_context and give each work packet a clone of tracer_context.
WARNING: object resurrection
If the VM binding retains an unreachable object for finalization, and the finalizer writes a reference of that object into a place readable by application threads, including global or static variable, then the previously unreachable object will become reachable by the application again. This phenomenon is known as "resurrection", and can be surprising to the programmers.
Developers of VM bindings of existing VMs may have no choice but to implement the finalizer
semantics strictly according to the specification of the VM, even if that would result in
"resurrection". JVM is a well-known example of the "resurrection" behavior, although the
Object.finalize() method has been deprecated for removal, in favor for alternative clean-up
mechanisms such as PhantomReference and Cleaner which never "resurrect" objects.
Designers of new programming languages or VMs should be aware of the "resurrection" problem. It is recommended not to let finalizers have access to the object body. For finalizers that need to release certain resources (such as files), the VM may store relevant data (such as file descriptors) in a separate object and use that as the context of the finalizer.
To avoid unintentionally "resurrecting" objects, if the VM binding intends to get the new address of
a moved object, it should use object.get_forwarded_object() instead of
tracer.trace_object(object), although the latter also returns the new address if object is
already moved.
Supporting weak references
The general way to handle weak references is, after computing the transitive closure, iterate through all fields that contain weak references. For each field,
- if the referent has already been reached, write the new address of the object to the field (or do nothing if the object is not moved);
- otherwise, clear the field, writing
null,nil, or whatever represents a cleared weak reference to the field.
Identifying weak references
Weak references in fields of global (per-VM) data structures are relatively straightforward. We
just need to enumerate them in Scanning::process_weak_refs.
There are also fields in heap objects that hold weak references to other heap objects. There are two basic ways to identify them.
- Register on creation: We may record objects that contain weak reference fields in a global
list when such objects are created. In
Scanning::process_weak_refs, we just need to iterate through this list, process the fields, and remove dead objects from the list. - Discover objects during tracing: While computing the transitive closure, we scan objects and
discover objects that contain weak reference fields. We enqueue such objects into a list, and
iterate through the list in
Scanning::process_weak_refsafter transitive closure. The list needs to be reconstructed in each GC.
Both methods work, but each has its advantages and disadvantages. Registering on creation does not need to reconstruct the list in every GC, while discovering during tracing can avoid visiting dead objects. Depending on the nature of your VM, one method may be easier to implement than the other, especially if your VM's existing GC has already implemented weak reference processing in some way.
Associated clean-up operations
Some languages and VMs allow certain clean-up operations to be associated with weak references, and will be executed after the weak reference is cleared.
Such clean-up operations can be supported similar to finalizers. While we enumerate weak references
in Scanning::process_weak_refs, we clear weak references to unreachable objects. Depending on the
semantics, we may choose to execute the clean-up operations immediately, or enqueue them to be
executed after GC. We may retain the unreachable referent if we need to.
Soft references
Java has a special kind of weak reference: SoftReference. The API allows the GC to choose between
(1) retaining softly reachable referents, and (2) clearing references to softly reachable objects.
When using MMTk, there are two ways to implement this semantics.
The easiest way is treating SoftReference as strong references in non-emergency GCs, and
treating them like WeakReference in emergency GCs.
- During non-emergency GC, we let
Scanning::scan_objectandScanning::scan_object_and_trace_edgesscan the weak reference field inside aSoftReferenceinstance as if it were an ordinary strong reference field. In this way, softly reachable objects will be included in the (strong) transitive closure from roots. By the first timeScanning::process_weak_refsis called, strongly reachable objects will have already been reached (i.e.object.is_reachable()will be true). They will be kept alive just like strongly reachable objects. - During emergency GC, however, skip this field in
Scanning::scan_objectorScanning::scan_object_and_trace_edges, and clearSoftReferencejust likeWeakReferenceinScanning::process_weak_refs. In this way, softly reachable objects will become unreachable unless they are subject to finalization.
The other way is retaining referents of SoftReference after the strong closure. This involves
supporting multiple levels of reference strength, which will be introduced in the next
section.
Multiple levels of reference strength
Some VMs support multiple levels of weak reference strengths. Java, for example, has
SoftReference, WeakReference, FinalizerReference (internal) and PhantomReference, in the
order of decreasing strength.
This can be supported by running Scanning::process_weak_refs multiple times. If
process_weak_refs returns true, it will be called again after all pending work packets in the
VMRefClosure stage has been executed. Those pending work packets include all work packets that
compute the transitive closure from objects retained during process_weak_refs. This allows the VM
binding to expand the transitive closure multiple times, each handling weak references at different
levels of strength.
Take Java as an example, we may run process_weak_refs four times.
- Visit all
SoftReference.- If the referent has been reached, then
- forward the referent field.
- If the referent has not been reached, yet, then
- if it is not an emergency GC, then
- retain the referent and update the referent field.
- it it is an emergency GC, then
- clear the referent field,
- remove the
SoftReferencefrom the list of soft references, and - optionally enqueue it to the associated
ReferenceQueueif it has one.
- if it is not an emergency GC, then
- (This step may expand the transitive closure in non-emergency GCs if any referents are retained.)
- If the referent has been reached, then
- Visit all
WeakReference.- If the referent has been reached, then
- forward the referent field.
- If the referent has not been reached, yet, then
- clear the referent field,
- remove the
WeakReferencefrom the list of weak references, and - optionally enqueue it to the associated
ReferenceQueueif it has one.
- (This step cannot expand the transitive closure.)
- If the referent has been reached, then
- Visit the list of finalizable objects.
- If the finalizable object has been reached, then
- forward the reference in the list.
- If the finalizable object has not been reached, yet, then
- retain the finalizable object, and
- remove it from the list of finalizable objects, and
- enqueue it for finalization.
- (This step may expand the transitive closure if any finalizable objects are retained.)
- If the finalizable object has been reached, then
- Visit all
PhantomReference.- If the referent has been reached, then
- forward the referent field.
- (Note:
PhantomReference#get()always returnsnull, but the actual referent field shall hold a valid reference to the referent before it is cleared.)
- If the referent has not been reached, yet, then
- clear the referent field,
- remove the
PhantomReferencefrom the list of phantom references, and - optionally enqueue it to the associated
ReferenceQueueif it has one.
- (This step cannot expand the transitive closure.)
- If the referent has been reached, then
As an optimization,
- Step 1 can be, as we described in the previous section, eliminated by
merging it with the strong closure in non-emergency GC, or with
WeakReferenceprocessing in emergency GCs. - Step 2 can be merged with Step 3 since Step 2 never expands the transitive closure.
Therefore, we only need to run process_weak_refs twice:
- Handle
WeakReference(and alsoSoftReferencein emergency GCs), and then handle finalizable objects. - Handle
PhandomReference.
To implement this, the VM binding may need to implement some kind of state machine so that the
Scanning::process_weak_refs function behaves differently each time it is called. For example,
#![allow(unused)] fn main() { fn process_weak_refs(...) -> bool { let mut state = /* Get VM-specific states here. */; match *state { State::ProcessSoftReference => { process_soft_references(...); *state = State::ProcessWeakReference; return true; // Run this function again. } State::ProcessWeakReference => { process_weak_references(...); *state = State::ProcessFinalizableObjects; return true; // Run this function again. } State::ProcessFinalizableObjects => { process_finalizable_objects(...); *state = State::ProcessPhantomReferences; return true; // Run this function again. } State::ProcessPhantomReferences => { process_phantom_references(...); *state = State::ProcessSoftReference return false; // Proceed to the Release stage. } } } }
Ephemerons
An Ephemeron has a key and a value, both of which are object references. The key is a weak reference, while the value keeps the referent alive only if both the ephemeron itself and the key are reachable.
To support ephemerons, the VM binding needs to identify ephemerons. This includes ephemerons as individual objects, objects that contain ephemerons, and, equivalently, objects that contain key/value fields that have semantics similar to ephemerons.
The following is an algorithm for processing ephemerons. It gradually discovers ephemerons as we do
the tracing. We maintain a queue of ephemerons which is empty before the Closure stage.
- In
Scanning::scan_objectandScanning::scan_object_and_trace_edges, we enqueue ephemerons (into the queue of ephemerons we created before) as we scan them, but do not trace either the key or the value fields. - In
Scanning::process_weak_refs, we iterate through all ephemerons in the queue. If the key of an ephemeron has been reached, but its value has not yet been reached, then retain its value, and remove the ephemeron from the queue. Otherwise, keep the object in the queue. - If any value is retained, return
truefromScanning::process_weak_refsso that it will be called again after the transitive closure from retained values are computed. Then go back to Step 2. - If no value is retained, the algorithm completes. The queue contains reachable ephemerons that have unreachable keys.
This algorithm can be modified if we have a list of all ephemerons before GC starts. We no longer need to maintain the queue.
- In Step 1, we don't need to enqueue ephemerons or trace their key or value fields.
- In Step 2, we iterate through all ephemerons. We retain the value if both the ephemeron itself and the key have been reached, and the value has not been reached, yet. We don't need to remove any ephemeron from the list.
- When the algorithm completes, we can identify both reachable and unreachable ephemerons that
have unreachable keys. But we need to remove unreachable (dead) ephemerons from the list
because they will be recycled in the
Releasestage.
And we can go through ephemerons with unreachable keys and do necessary clean-up operations, either immediately or postponed to mutator time.
Optimizations
Generational GC
MMTk provides generational GC plans. Currently, there are GenCopy, GenImmix and StickyImmix.
In a minor GC, a generational plan only consider young objects (i.e. objects allocated since the
last GC) as candidates of garbage, and will assume all old objects (i.e. objects survived the last
GC) are live.
The VM binding can query if the current GC is a nursery GC by calling
#![allow(unused)] fn main() { let is_nursery_gc = mmtk.get_plan().generational().is_some_and(|gen| gen.is_current_gc_nursery()); }
The VM binding can make use of this information when processing finalizers and weak references. In a minor GC,
- The VM binding only needs to visit finalizable objects allocated since the last GC. Other finalizable objects must be old and will not be considered dead.
- The VM binding only needs to visit weak reference slots written since the last GC. Other
slots must be pointing to old objects (if not
null). For weak hash tables, if existing entries are immutable, it is sufficient to only visit newly added entries.
Implementation-wise, the VM binding can split the lists or hash tables into two parts: one for old entries and another for young entries.
Copying versus non-copying GC
MMTk provides both copying and non-copying GC plans. MarkSweep never moves any objects.
MarkCompact, SemiSpace always moves all objects (except objects in the large object space,
immortal space, VM space, etc.). Immix-based plans sometimes do non-copying GC, and sometimes do
copying GC. Regardless of the plan, the VM binding can query if the current GC is a copying GC by
calling
#![allow(unused)] fn main() { let may_move_object = mmtk.get_plan().current_gc_may_move_object(); }
If it returns false, the current GC will not move any object.
The VM binding can make use of this information. For example, if a weak hash table uses object addresses as keys, and the hash code is computed directly from the address, then the VM will need to rehash the table during copying GC because changing the address may move the entry to a different hash bin. But if the current GC is non-moving, the VM binding will not need to rehash the table, but only needs to remove entries for dead objects. Despite of this optimization opportunity, we still recommend VMs to implement address-based hashing if possible. In that case, we never need to rehash any hash tables due to object movement.
When using address-based hashing, the hash code of an object depends on whether its hash code has been observed before, and whether it has been moved after its hash code has been observed.
- If never observed, the hash code of an object will be its current address.
- When the object is moved the first time after its hash code is observed, the GC thread copies its old address to a field of the new copy. From then on, its hash code will be read from that field.
- When such an object is copied again, its hash code will be copied to the new copy of the object. The hash code of the object remains unchanged.
The VM binding needs to implement this in ObjectModel::copy.
Deprecated reference and finalizable processors
When porting MMTk from JikesRVM to a dedicated Rust library, we also ported the ReferenceProcessor
and the FinalizableProcessor from JikesRVM. They are implemented in mmtk-core, and provide the
mechanisms for handling Java-style soft/weak/phantom references and finalizable objects. The VM
binding can use those utilities by implementing the mmtk::vm::ReferenceGlue and the
mmtk::vm::Finalizable traits, and calling the
mmtk::memory_manager::add_{soft,weak,phantom}_candidate and the
mmtk::memory_manager::add_finalizer functions.
However, those mechanisms are too specific to Java, and are not applicable to most other VMs. New
VM bindings should use the Scanning::process_weak_refs API, and we are porting existing VM
bindings away from the built-in reference/finalizable processors.
Address-based Hashing
Address-based hashing is a GC-assisted method for implementing identity hash code in copying GC. It has the advantage of high performance and not requiring a dedicated hash field for most objects.
This chapter is especially useful for VMs that previously used non-moving GC and naively used the object address as identity hash code.
Concepts
An identity hash code of an object is a hash code that never changes during the lifetime of the object, i.e. since it is allocated, until it is reclaimed by the GC.
- It is not required to be unique.
- Two different objects are allowed to have the same identity hash code. Like any hashing algorithm, collision is allowed. But a good hash code should be relatively unique in order to reduce collision.
- On the contrary, some programming languages (such as Python and Ruby) have the notion of object ID which is required to be unique.
- It is unrelated to the value the object represents.
- For example, modifying a mutable string object does not change its identity hash code.
- On the contrary, two string objects that are equal character-wise may (but does not have to) have different identity hash code.
- Copying GC does not change object identities.
- If an object is moved by a copying GC, its identity hash code remains the same.
- On the contrary, when moved by a copying GC, the address of the object is changed.
For non-copying GC algorithms, the address of an object never changes, and all objects have distinct addresses. Therefore it is an ideal identity hash code.
For copying GC algorithms, however, we cannot simply use the address of an object because it will be changed when the GC moves the object. A naive solution is adding an extra field to every object to hold its hash code, and the field is copied when the GC moves the object. Although this approach works (and it is used by real-world VMs such as OpenJDK), it unconditionally adds a field to every object. However,
- Objects are rarely moved in advanced GC algorithms such as Immix.
- Few objects ever have identity hash code observed (e.g. by calling
System.identityHashCode(object)in Java) in real-world applications. According to the Lilliput project of OpenJDK, with most workloads, only relatively few (<1%) Java objects are ever assigned an identity hash.
Address-based hashing solves these problems by not adding the extra hash field until both of the following conditions are true:
- The identity hash code of the object has been observed, and
- the object is moved by the GC after its identity hash code has been observed.
Under the weak generational hypothesis (i.e. most objects die young), most objects will die before the two conditions become true, and will never need the extra hash field during its lifetime.
The address-based hashing algorithm is implemented in JikesRVM, and is planned to be implemented in OpenJDK (the Lilliput project).
The Address-based Hashing Algorithm
Each object is in one of the three hash code states:
UnhashedHashedHashedAndMoved
The state-transition graph is shown below:
move hash move or hash
┌──────┐ ┌──────┐ ┌──────┐
│ │ │ │ │ │
┌────▼──────┴────┐ hash ┌────▼──────┴────┐ move ┌────▼──────┴────┐
│ Unhashed ├─────────►│ Hashed ├─────────►│ HashedAndMoved │
└────────────────┘ └────────────────┘ └────────────────┘
States are transitioned upon events labelled on the edges:
hash: The mutator observes the identity hash code of an object.move: The GC moves the object.
An object starts in the Unhashed state when allocated. The GC is free to move it any times, and
its state remains Unhashed, as long as its identity hash code is not observed.
When the identity hash code is observed for the first time, its state is changed to Hashed. In
the Hashed state, the identity hash code of an object is its address. The object will continue
to use its address as its identity hash code until the object is moved.
When a Hashed object is moved, the GC adds a hash field (distinct from high-level language fields
defined by the application) to the new copy of the object, and writes its old address into that
field. The state of the object is transitioned to HashedAndMoved. In the HashedAndMoved
state, the identity hash code of an object is the value in its added hash field, and it will keep
using the value in the field as the identity hash code from then on.
When a HashedAndMoved object is moved again, the GC copies the hash field to the newer copy, but
no state transition happens.
Implementing Address-based Hashing with MMTk
Here we use the implementation strategy from JikesRVM as an example of how to implement address-based hashing when using MMTk. For the best performance, we recommend holding the hash code state in the object header, and putting the added hash field in the beginning or the end of the object. We also introduce alternative strategies in the next section.
Object Layout
Since there are three states, each object needs two bits of metadata to represent that state. The two bits are usually held in the object header. For example, in JikesRVM, the two hash code state bits are placed after the thin lock bits, as shown below.
TTTT TTTT TTTT TTTT TTTT TTHH AAAA AAAA
T = thin lock bits
H = hash code state bits
A = available for use by GCHeader and/or MiscHeader.
The VM also needs to decide the location of the extra hash field. It is usually placed at the
beginning or at the end of an object, as shown in the diagram below. Regardless of the position of
the hash field, the ObjectReference of an object usually points at the object header. In this
way, the header and ordinary fields can be accessed at the same offsets from the ObjectReference
regardless of whether or where the hash field has been added. The starting address of the object,
however, may no longer be the same as he ObjectReference in some layout designs. Therefore, the
VM binding needs to implement ObjectModel::ref_to_object_start and handle the added hash field
correctly.
│ObjectReference
│start of object
▼
┌────────────┬──────────────────────────┐
No hash field │ Header │ ordinary fields... │
└────────────┴──────────────────────────┘
│start of │
│object │ObjectReference
▼ ▼
┌────────────┬────────────┬──────────────────────────┐
Hash at the beginning │ Hash │ Header │ ordinary fields... │
└────────────┴────────────┴──────────────────────────┘
│ObjectReference
│start of object
▼
┌────────────┬──────────────────────────┬────────────┐
Hash at the end │ Header │ ordinary fields... │ Hash │
└────────────┴──────────────────────────┴────────────┘
GC: Copying Objects
MMTk calls the following trait methods implemented by the VM binding during copying GC.
- For non-delayed-copy collectors (all moving plans except MarkCompact)
ObjectModel::copy
- For delayed-copy collectors (MarkCompact)
ObjectModel::copy_toObjectModel::get_reference_when_copied_toObjectModel::get_size_when_copiedObjectModel::get_align_when_copiedObjectModel::get_align_offset_when_copied
When using a non-delayed-copy collector, MMTk calls ObjectModel::copy which is defined as:
#![allow(unused)] fn main() { fn copy( from: ObjectReference, semantics: CopySemantics, copy_context: &mut GCWorkerCopyContext<VM>, ) -> ObjectReference; }
The copy method should
- Find the state of the
fromobject. This is done in VM-specific ways, such as inspecting header bits. If it wasHashed, it should transition to theHashedAndMovedstate in the new copy. - Find the size of the
fromobject, including the hash field. If thefromobject is already in theHashedAndMovedstate, the VM binding must have already inserted a hash field in step 3 below. Make sure the hash field is counted in the object size. - Allocate the new copy, with a larger size if needed. It should call
copy_context.alloc_copy(from, new_size, new_align, new_offset, semantics)to allocate the new copy of the object. When transitioning fromHashedtoHashedAndMoved, thenew_sizeshould be larger than the old size in order to accommodate the added hash field. Otherwise the new size should be the same as the old size. - Adjust the
ObjectReferenceif needed. If the hash field is inserted in the beginning, the offset from the start of the object to theObjectReferencemay be greater in the new copy. Make sure theObjectReferenceof the new copy is pointing at the right place. See the diagrams in the Object Layout section. - Copy header and ordinary fields. Make sure the data is copied to the right offset if the hash field is inserted at the beginning.
- Fix the state of the new copy if needed. If the old copy is
Hashed, the new copy shall be in theHashedAndMovedstate. Set the new copy to the right state by, for example, modifying its header bits. - Write or copy the hash field if needed. When transitioning from
HashedtoHashedAndMoved, write the old address of the object to the hash field; if the old copy is already in theHashedAndMovedstate, copy the content of the hash field.
When using a delayed-copy collector, the VM binding should do the same things as above, but in
different methods in a slightly different order. It shall (1) determine the size of the new copy in
get_size_when_copied, (2) determine the address of ObjectReference in the new copy in
get_reference_when_copied_to, and (3) do the actual copying and write the right values to the
header bits and the hash field in copy_to. The reference to the old copy is passed to all of the
three methods as a parameter so that the VM binding can look up the state of the old copy, and
determine the state of the new copy.
Mutator: Observing the Identity Hash Code
Mutators should get the identity hash code of an object by first finding the state of the object.
- If
Unhashed, it should set its state toHashedand use its address as the hash code. - If
Hashed, it should simply use its address as the hash code. - If
HashedAndMoved, it should read the hash code from the added hash field.
Note that the operation of getting the identity hash code may happen concurrently with other mutator threads and GC worker threads.
Because other mutators can be accessing the header bits of the same object concurrently, the
operation of transitioning the state from Unhashed to Hashed it should be done atomically.
If, as in JikesRVM, the Unhashed state is encoded as 00 and the Hashed state is encoded as
01, this state transition can be done with a single atomic bit-set or fetch-or operation.
There is also a risk if GC can happen concurrently, moving the object and changing its state. If copying only happens during stop-the-world (that includes all stop-the-world GC algorithms and some concurrent GC algorithms that only copy objects during stop-the-world, such as LXR), we can make the computing of identity hash code atomic with respect to copying GC by not inserting GC-safe points in the middle of computing identity hash code. MMTk currently does not have concurrent copying GC.
Alternative Implementation Strategies
Some VMs cannot implement address-based hashing in the same way as JikesRVM due to implementation details.
If the VM cannot spare two bits in the object header for the hash code state, it can use on-the-side metadata (bitmap), instead. It will add a space overhead of two bits per object alignment. If all objects are aligned to 8 bytes, it will be a 1/32 (about 3%) space overhead.
If the VM cannot add a hash field to an object when moved, an alternative is using a global table
that maps the address of each object in the HashedAndMoved state to its hash code. This will
require a table lookup every time the VM observes the hash code of an object in the HashedAndMoved
state. This table also needs to be updated when copying GC happens because object may be moved or
dead. Because the addresses of objects are used as keys, the table may need to be rehashed or
reconstructed if it is implemented as a hash table or a search tree.
Whether the space and time overhead is acceptable depends on the VM implementation as well as the
workload. For example, if a VM has many hash tables that naively use object addresses as the hash
code, it will need to rehash all such tables when copying GC happens. Even though maintaining a
global table that maps addresses to hash codes is expensive, implementing address-based hashing this
way can still eliminate the need to rehash all other hash tables at the expense of having to rehash
one global table. And if very few objects are in the HashedAndMoved state, the average cost of
computing the identity hash code can still be low.
API Migration Guide
This document lists changes to the MMTk-VM API that require changes to be made by the VM bindings. VM binding developers can use this document as a guide to update their code to maintain compatibility with the latest release of MMTk.
View control
Choose how many details you want to read.
0.33.0
Collection enabling/disabling is now managed by MMTk instead of the VM binding
Collection::is_collection_enabled() is removed. MMTk now tracks whether collection is enabled
itself, via the new, nestable disable_collection()/enable_collection() API on MMTK (and
memory_manager).
API changes:
- trait
vm::Collectionis_collection_enabled(): Removed.- Previously, the VM binding implemented this method to tell MMTk whether GC is currently allowed. MMTk now manages this state itself, so the binding no longer needs to (and no longer can) answer this question.
- If the binding previously disabled collection at certain times (e.g. before some
initialization completed), it should instead call the new
memory_manager::disable_collection()at the point where it used to start returningfalse, andmemory_manager::enable_collection()at the point where it used to start returningtrueagain.
- module
memory_managerdisable_collection(): now returnsResult<bool, GcStatus>.Ok(true)means this call actually switched collection from enabled to disabled;Ok(false)means it only increased the nesting depth of an already-disabled status.Err(status)means collection could not be disabled right now, withstatusnaming why (e.g. a GC is in progress or has been requested); the VM binding should check safepoints, expect a pause, or wait for the concurrent GC to finish, then call this function again.
enable_collection(): return true if the GC is enabled after the call. Otherwise, the function returns false.
is_collection_enabled(): New. Returns whether collection is currently enabled.
See also:
Slot is required to implement Sync
API changes:
- module
vm::slotSlot: Now required to implementSync- The provided
SimpleSlotin mmtk-core already implementsSync. If the VM binding uses it, no change is needed. - If the VM binding's
Slotimplementation does not include raw pointers (*const Tand*mut T), chance is high that it automatically implementsSync. If this is the case, no change is needed. - Otherwise, the VM binding should declare
unsafe impl Sync for ...for the slot type.
- The provided
Thread IDs require Debug instead of Display
API changes:
- module
util::osOS::ThreadIDType: This associated type now requiresDebuginstead ofDisplay.- This allows platforms where the native thread ID type does not implement
Display, such aslibc::pthread_ton musl. - Bindings that provide an OS implementation should derive or implement
Debugfor their thread ID type.
- This allows platforms where the native thread ID type does not implement
The <'w> lifetime in ObjectTracerContext
API changes:
- module
vm::scanningObjectTracerContext::TracerType: Now has a<'w>lifetime parameterObjectTracerContext::with_tracer: Now has a<'w>lifetime parameter'wis the lifetime of theworkerargument, and is passed to theSelf::TracerType<'w>argument of thefunccallback. It basically means theObjectTracerprovided to thefunccallback borrows theworkerduring the callback. This has always been true, but we now made it explicit through the lifetime parameter.
Type argument changes in Finalizable::keep_alive module
API changes:
- module
vm::reference_glueFinalizable::keep_alive: Now has the<OT: ObjectTracer>type parameter instead of<E: ProcessEdgesWork>. Thetraceparameter is now&mut OT. It still has thetrace_objectmethod like the oldProcessEdgesWorktrait, and is supposed to be used the same way.
The Cargo feature "is_mmtk_object" is removed
The "is_mmtk_object" cargo feature is removed. Anything previously enabled by the "is_mmtk_object" feature are now enabled by the "vo_bit" feature.
API changes: None. If a VM binding uses the "is_mmtk_object" feature, it should now use the "vo_bit" feature if not already using, and existing code should still compile.
Side metadata base addresses are no longer constants
Side metadata addresses are now chosen at runtime. The old address constants are removed and replaced with accessor functions that must only be called after MMTk is initialized.
API changes:
- module
util::metadata::side_metadataGLOBAL_SIDE_METADATA_BASE_ADDRESS: Removed.- Use
global_side_metadata_base_address()instead.
- Use
GLOBAL_SIDE_METADATA_VM_BASE_ADDRESS: Removed.- Use
global_side_metadata_vm_base_address()instead.
- Use
VO_BIT_SIDE_METADATA_ADDR: Removed.- Use
vo_bit_side_metadata_addr()instead.
- Use
- module
util::metadata::vo_bitVO_BIT_SIDE_METADATA_ADDR: Removed.- Use
vo_bit_side_metadata_addr()instead.
- Use
These addresses are no longer constants because MMTk now chooses the side metadata base address at boot time. Bindings should fetch them from the accessor functions after MMTk initialization has completed. Bindings can assume the addresses will not change once they are initialized.
0.32.0
Allocation options changed
AllocationOptions now has multiple boolean fields instead of one OnAllocationFail field. Now
polling cannot be disabled. Instead we can now poll and over-commit in one allocation.
API changes:
- module
util::alloc::allocatorOnAllocationFail: Removed.AllocationOptions: It now has two boolean fields:allow_overcommitat_safepointallow_oom_call
Variants of the old enum OnAllocationFail should be migrated to the new API according to the
following table:
| variant | allow_overcommit | at_safepoint | allow_oom_call |
|---|---|---|---|
RequestGC | false | true | true |
ReturnFailure | false | false | false |
OverCommit | true | false | false |
Note that MMTk now always polls before trying to get more pages from the page resource, and it may
trigger GC. The old OnAllocationFail::OverCommit used to prevent polling, but it is no longer
possible.
See also:
Removed the notion of "mmap chunk"
Constants such as MMAP_CHUNK_BYTES were related to the implementation details of the memory
mapper, and should not have been exposed.
API changes:
- module
util::conversionsmmap_chunk_align_down: Removed.mmap_chunk_align_up: Removed.
- module
util::heap::vm_layoutLOG_MMAP_CHUNK_BYTES: Removed.MMAP_CHUNK_BYTES: Removed.
Options no longer differentiates between environment variables and command line arguments.
We replaced both Options::set_from_command_line and Options::set_from_env_var with
Options::set_from_string because all options can now be set via either environment variable or
command line arguments.
API changes:
- module
util::optionsOptions::set_from_command_line: Removed.- Use
Options::set_from_stringinstead.
- Use
Options::set_from_env_var: Removed.- Use
Options::set_from_stringinstead.
- Use
Options::set_bulk_from_command_line: Removed.- Use
Options::set_bulk_from_stringinstead.
- Use
- All
<T>inMMTKOption<T>now must implementFromStr.- This means you can parse a string into
Twhen setting anMMTKOption<T>. For example,options.plan.set(user_input.parse()?);.
- This means you can parse a string into
The feature immix_stress_copying is removed.
The feature immix_stress_copying is removed. Bindings can use MMTk options with the following values
to achieve the same behavior as before: immix_always_defrag=true,immix_defrag_every_block=true,immix_defrag_headroom_percent=50
API changes:
- The feature
immix_stress_copyingis removed. - module
util::optionsOptionsincludesimmix_always_defrag, which defaults tofalse.Optionsincludesimmix_defrag_every_block, which defaults tofalse.Optionsincludesimmix_defrag_headroom_percent, which defaults to2.
See also:
0.30.0
live_bytes_in_last_gc becomes a runtime option, and returns a map for live bytes in each space
count_live_bytes_in_gc is now a runtime option instead of a features (build-time), and we collect
live bytes statistics per space. Correspondingly, memory_manager::live_bytes_in_last_gc now returns a map for
live bytes in each space.
API changes:
- module
util::optionsOptionsincludescount_live_bytes_in_gc, which defaults tofalse. This can be turned on at run-time.- The old
count_live_bytes_in_gcfeature is removed.
- module
memory_managerlive_bytes_in_last_gcnow returns aHashMap<&'static str, LiveBytesStats>. The keys are strings for space names, and the values are statistics for live bytes in the space.
See also:
mmap-related functions require annotation
Memory-mapping functions in mmtk::util::memory now take an additional MmapAnnotation argument.
API changes:
- module
util::memory- The following functions take an additional
MmapAnnotationargument.dzmmapdzmmap_noreplacemmap_noreserve
- The following functions take an additional
0.28.0
handle_user_collection_request returns bool
memory_manager::handle_user_collection_request now returns a boolean value to indicate whether a GC
is triggered by the method or not. Bindings may use the return value to do some post-gc cleanup, or
simply ignore the return value.
API changes:
- module
memory_managerhandle_user_collection_requestnow returnsboolto indicate if a GC is triggered by the method. Bindings may use the value, or simply ignore it.
See also:
- PR: https://github.com/mmtk/mmtk-core/issues/1205
- Examples:
- https://github.com/mmtk/mmtk-julia/pull/177: Ignore return value.
ObjectReference must point inside an object
ObjectReference is now required to be an address within an object. The concept of "in-object
address" and related methods are removed. Some methods which used to depend on the "in-object
address" no longer need the <VM> type argument.
API changes:
- struct
ObjectReference- Its "raw address" must be within an object now.
- The following methods which were used to access the in-object address are removed.
from_addressto_address- When accessing side metadata, the "raw address" should be used, instead.
- The following methods no longer have the
<VM>type argument.get_forwarded_objectis_in_any_spaceis_liveis_movableis_reachable
- module
memory_manageris_mmtk_object: It now requires the address parameter to be non-zero and word-aligned.- Otherwise it will not be a legal
ObjectReferencein the first place. The user should filter out such illegal values.
- Otherwise it will not be a legal
- The following functions no longer have the
<VM>type argument.find_object_from_internal_pointeris_in_mmtk_spaceis_live_objectis_pinnedpin_objectunpin_object
- struct
Region- The following methods no longer have the
<VM>type argument.containing
- The following methods no longer have the
- trait
ObjectModelIN_OBJECT_ADDRESS_OFFSET: removed because it is no longer needed.
See also:
- PR: https://github.com/mmtk/mmtk-core/issues/1170
- Examples:
- https://github.com/mmtk/mmtk-openjdk/pull/286: a simple case
- https://github.com/mmtk/mmtk-jikesrvm/issues/178: a VM that needs much change for this
0.27.0
is_mmtk_object returns Option<ObjectReference>
memory_manager::is_mmtk_object now returns Option<ObjectReference> instead of bool.
Bindings can use the returned object reference instead of computing the object reference at the binding side.
API changes:
- module
memory_manageris_mmtk_objectnow returnsOption<ObjectReference>.
See also:
Introduce ObjectModel::IN_OBJECT_ADDRESS_OFFSET
We used to have ObjectModel::ref_to_address and ObjectModel::address_to_ref, and require
the object reference and the in-object address to have a constant offset. Now, the two methods
are removed, and replaced with a constant ObjectModel::IN_OBJECT_ADDRESS_OFFSET.
API changes:
- trait
ObjectModel- The methods
ref_to_addressandaddress_to_refare removed. - Users are required to specify
IN_OBJECT_ADDRESS_OFFSETinstead, which is the offset from the object reference to the in-object address (the in-object address was the return value for the oldref_to_address()).
- The methods
- type
ObjectReference- Add a constant
ALIGNMENTwhich equals to the word size. All object references should be at least aligned to the word size. This is checked in debug builds when anObjectReferenceis constructed.
- Add a constant
See also:
- PR: https://github.com/mmtk/mmtk-core/pull/1159
- Example: https://github.com/mmtk/mmtk-openjdk/pull/283
0.26.0
Rename "edge" to "slot"
The word "edge" in many identifiers have been changed to "slot" if it actaully means slot.
Notable items include the traits Edge, EdgeVisitor, the module edge_shape, and member types
and functions in the Scanning and VMBinding traits. The VM bindings should not only make
changes in response to the changes in MMTk-core, but also make changes to their own identifiers if
they also use "edge" where it should have been "slot". The find/replace tools in text editors and
the refactoring/renaming tools in IDEs should be helpful.
API changes:
- module
edge_shape->slot - type
RootsWorkFactory<ES: Edge>-><SL: Slot>create_process_edge_roots_work->create_process_roots_work
- type
SimpleEdge->SimpleSlot - type
UnimplementedMemorySliceEdgeIterator->UnimplementedMemorySliceSlotIterator - trait
Edge->Slot - trait
EdgeVisitor->SlotVisitor<ES: Edge>-><SL: Slot>visit_edge->visit_slot
- trait
MemorySliceEdge->SlotTypeEdgeIterator->SlotIteratoriter_edges->iter_slots
- trait
Scanningsupport_edge_enqueuing->support_slot_enqueuingscan_object<EV: EdgeVisitor>-><SV: SlotVisitor>
scan_roots_in_mutator_thread- Type parameter of
factorychanged. See typeRootsWorkFactory.
- Type parameter of
scan_vm_specific_roots- Same as above.
- trait
VMBindingVMEdge->VMSlot
See also:
- PR: https://github.com/mmtk/mmtk-core/pull/1134
- Example: https://github.com/mmtk/mmtk-openjdk/pull/274
0.25.0
ObjectReference is no longer nullable
ObjectReference can no longer represent a NULL reference. Some methods of ObjectReference and
the write barrier functions in memory_manager are changed. VM bindings need to re-implement
methods of the Edge, ObjectModel and ReferenceGlue traits.
API changes:
- type
ObjectReference- It can no longer represent NULL reference.
- It is now backed by
NonZeroUsize, and MMTk usesOption<ObjectReference>universally when anObjectReferencemay or may not exist. It is more idiomatic in Rust.
- It is now backed by
- The constant
ObjectReference::NULLis removed. is_null()is removed.from_raw_address(addr)- The return type is changed to
Option<ObjectReference>. - It returns
Noneifaddris not zero. - If you know
addrcannot be zero, you can use the new methodfrom_raw_address_unchecked(addr), instead.
- The return type is changed to
- It can no longer represent NULL reference.
- module
mmtk::memory_manager- Only affects users of write barriers
object_reference_write_pre(mutator, obj, slot, target)- The
targetparameter is nowOption<ObjectReference>. - Pass
Noneif the slot was holding a NULL reference or any non-reference value.
- The
object_reference_write_post(mutator, obj, slot, target)- Same as above.
object_reference_write(mutator, obj, slot, target)- It is labelled as
#[deprecated]and needs to be redesigned. It cannot handle the case of storing a non-reference value (such as tagged small integer) into the slot. - Before a replacement is available, use
object_reference_write_preandobject_reference_write_post, instead.
- It is labelled as
- trait
Edgeload()- The return type is changed to
Option<ObjectReference>. - It returns
Noneif the slot is holding a NULL reference or other non-reference values. MMTk will skip those slots.
- The return type is changed to
- trait
ObjectModelcopy(from, semantics, copy_context)- Previously VM bindings convert the result of
copy_context.alloc_copy()toObjectReferenceusingObjectReference::from_raw_address(). - Because
CopyContext::alloc_copy()never returns zero, you can useObjectReference::from_raw_address_unchecked()to skip the zero check.
- Previously VM bindings convert the result of
get_reference_when_copied_to(from, to)tois never zero because MMTk only calls this after the destination is determined.- You may skip the zero check, too.
address_to_ref(addr)addris never zero because this method is an inverse operation ofref_to_address(objref)whereobjrefis never NULL.- You may skip the zero check, too.
- trait
ReferenceGlue- Note: If your VM binding is still using
ReferenceGlueand the reference processor and finalization processor in mmtk-core, it is strongly recommended to switch to theScanning::process_weak_refsmethod and implement weak reference and finalization processing on the VM side. get_referent()- The return type is changed to
Option<ObjectReference>. - It now returns
Noneif the referent is cleared.
- The return type is changed to
clear_referent()- It now needs to be explicitly implemented because
ObjectReference::NULLno longer exists. - Note: The
Edgetrait does not have a method for storing NULL to a slot. The VM binding needs to implement its own method to store NULL to a slot.
- It now needs to be explicitly implemented because
- Note: If your VM binding is still using
Not API change, but worth noting:
- Functions that return
Option<ObjectReference>memory_manager::get_finalized_objectObjectReference::get_forwarded_object- The functions listed above did not change, as they still return
Option<ObjectReference>. But some VM bindings used to expose them to native programs by wrapping them intoextern "C"functions that returnObjectReference, and returnObjectReference::NULLforNone. This is no longer possible since we removedObjectReference::NULL. The VM bindings should usemmtk::util::api_util::NullableObjectReferencefor the return type instead.
- The functions listed above did not change, as they still return
See also:
- PR: https://github.com/mmtk/mmtk-core/pull/1064
- PR: https://github.com/mmtk/mmtk-core/pull/1130 (for write barriers)
- Example: https://github.com/mmtk/mmtk-openjdk/pull/265
- Example: https://github.com/mmtk/mmtk-openjdk/pull/273 (for write barriers)
Instance methods of ObjectReference changed
Some methods of ObjectReference now have a type parameter <VM>. ObjectReference::value() is
removed.
API changes:
- type
ObjectReference- The following methods now require a generic argument
<VM: VMBinding>:ObjectReference::is_reachableObjectReference::is_liveObjectReference::is_movableObjectReference::get_forwarded_objectObjectReference::is_in_any_spaceObjectReference::is_sane
ObjectReference::value()is removed.- Use
ObjectReference::to_raw_address()instead.
- Use
- The following methods now require a generic argument
See also:
- PR: https://github.com/mmtk/mmtk-core/pull/1122
- Example: https://github.com/mmtk/mmtk-openjdk/pull/272
The GC controller (a.k.a. coordinator) is removed
The GC controller thread is removed from MMTk core. The VM binding needs to re-implement
Collection::spawn_gc_thread and call GCWorker::run differently.
API changes:
- type
GCWorkerGCWorker::run- It now takes ownership of the
Box<GCWorker>instance instead of borrowing it. - The VM binding can simply call the method
worker.run()on the worker instance fromGCThreadContext::Worker(worker).
- It now takes ownership of the
- module
mmtk::memory_managerstart_worker- It is now a simple wrapper of
GCWorker::runfor legacy code. It takes ownership of theBox<GCWorker>instance, too.
- It is now a simple wrapper of
- trait
CollectionCollection::spawn_gc_thread- It no longer asks the binding to spawn the controller thread.
- The VM binding can simply remove the code path related to creating the controller thread.
- Note the API change when calling
GCWorker::runorstart_worker.
See also:
Contributors
This is a list of the contributors who helped writing and improving this document. We deeply appreciate your commitment to making this work the best it can be. Thank you for your contribution.
- Rouane Bannister (rouanebannister)
- Angus Atkinson (angussidney)
- Brenda Wang
- Steve Blackburn (steveblackburn)
- Kunal Sareen (k-sareen)
- Yi Lin (qinsoon)